November 2022 safety news: Mode collapse in InstructGPT, Adversarial Go

Better version of the monthly Twitter thread.
Adversarial Policies Beat Professional-Level Go AIs
Adversarial policies in Go. Policies trained on self-play can be exploited by adversarially playing towards an out-of-distribution state of the board.
The adversary is trained via a simple AlphaZero-like tree search method.
Does this spell trouble for RL deployed in the real world?

Note also the slight controversy in the followups:
The failure of naive self play to produce unexploitable policies is textbook level material (Multiagent Systems, http://masfoundations.org/mas.pdf), and methods that produce less exploitable policies have been studied for decades (…)
Hopefully these pointers will help future researchers to address interesting new problems rather than empirically rediscovering known facts.
Reply by Adam Gleave (one of the authors):
I can see why a MAS scholar would be unsurprised by this result. However, most ML experts we spoke to prior to this paper thought our attack would fail! (…)
Ultimately self-play continues to be a widely used method, with high-profile empirical successes such as AlphaZero and OpenAI Five. If even these success stories are so empirically vulnerable we think it’s important for their limitations to become established common knowledge.
I reached out to Adam Gleave and the explanation was rather convincing:
It is indeed unsurprising that self-play is exploitable.
But the fact that the exploit wins by a large margin, is just one edge case, is easily found with small fraction of compute, etc are significant to its practical relevance. The theory doesn't really make predictions either way there.
See also the updated OpenReview version and explore the Go games. The adversary wins in a qualitatively different way, not relying on the intricacies of Go rules:

Mysteries of mode collapse
Base language models such as GPT-3 have diverse outputs. On the other hand, InstructGPT models behave very consistently, like a single agent.

Examples of evidence: `text-davinci-002` has a favorite number, and often starts with “there is no correct answer to this question”:

See also this comment by gwern, containing gems such as:
GPT-3 is always trying to solve the POMDP of the family of tasks which is 'the Internet', where data is generated by processes drawing from a distribution of human & other agents to roleplay, and it is reducing uncertainty by inferring which agent it is in this particular sample. In RLHF, the uncertainty collapses: there is, quite literally, a single deterministic agent — the reward model, as defined by the synthesis of the lowest common denominator of all the crowdworkers giving ratings ground up into a dataset of i.i.d. pink slime text.
So, since it is an agent, it seems important to ask, which agent, exactly? The answer is apparently: a clerk which is good at slavishly following instructions, but brainwashed into mealymouthedness and dullness, and where not a mealymouthed windbag shamelessly equivocating, hopelessly closed-minded and fixated on a single answer.
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
RLHF on multimodal agents. DeepMind trained a reward model on binary feedback from people rating model actions. Reinforcement learning agents trained on the reward model outperform plain behavioral cloning of human actions.
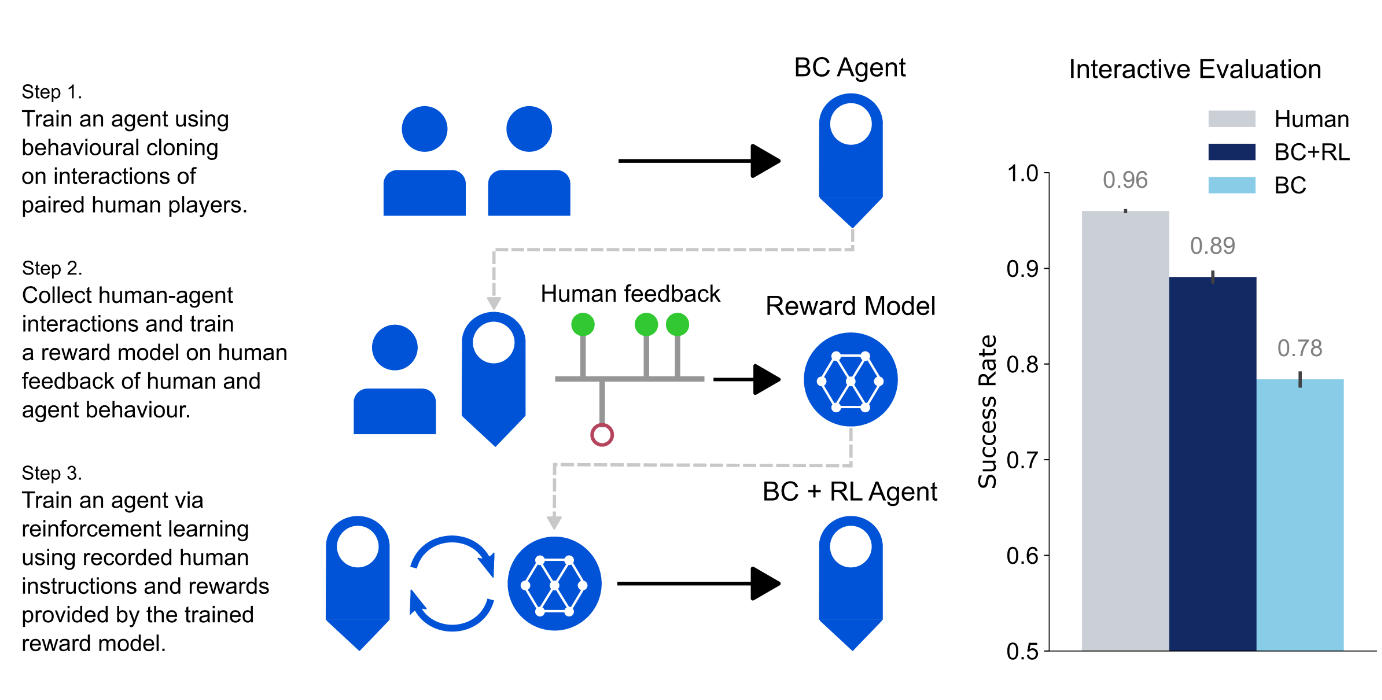
No signs of RLHF accidentally producing bad behavior yet!
See also Davis Blalock’s more detailed commentary.
Holistic Evaluation of Language Models
Holistic evaluation of LLMs. Huge benchmark paper covering both capabilities and failure modes, in 16 different scenarios, with standardized evaluation setups.

I appreciate the focus on metrics other than accuracy! Training models already optimizes for performance on accuracy benchmarks; for keeping models safe, it’s important to track performance on metrics that are not explicitly trained for.
Measuring Progress on Scalable Oversight for Large Language Models
Anthropic paper on scalable oversight. How to use AI to supervise very powerful AI models better?
They do a proof-of-concept of Ajeya Cotra’s "sandwiching": black-box dialogue interaction can help non-experts reach expert level performance on MMLU and QuALITY benchmarks.
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Indirect Object Identification (IOI) is a task of predicting which word in the previous sentence is the object in the next sentence.

They find the largest interpretable circuit in a GPT to date, solving the IOI task in gpt2-small. The circuit implements the following steps:
Find all previous names in the sentence;
Remove all names that are duplicates;
Output the remaining name.
This is the circuit:

Overall I’m quite happy this research is progressing, but the fact that the IOI task is the best we can do with in mechanistic interpretability right now updates me towards NO on this famous market on Manifold.
Note that the lead author is still in high school. Who knows what black box algorithms will be interpretable by the time they do a PhD?

Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
Will we run out of data? Epoch is a cool new org doing economics-style research on the AI landscape. They released a paper saying human-written high quality language data will be exhausted by 2026. So, LLM scaling without some kind of self-improvement might stop soon!
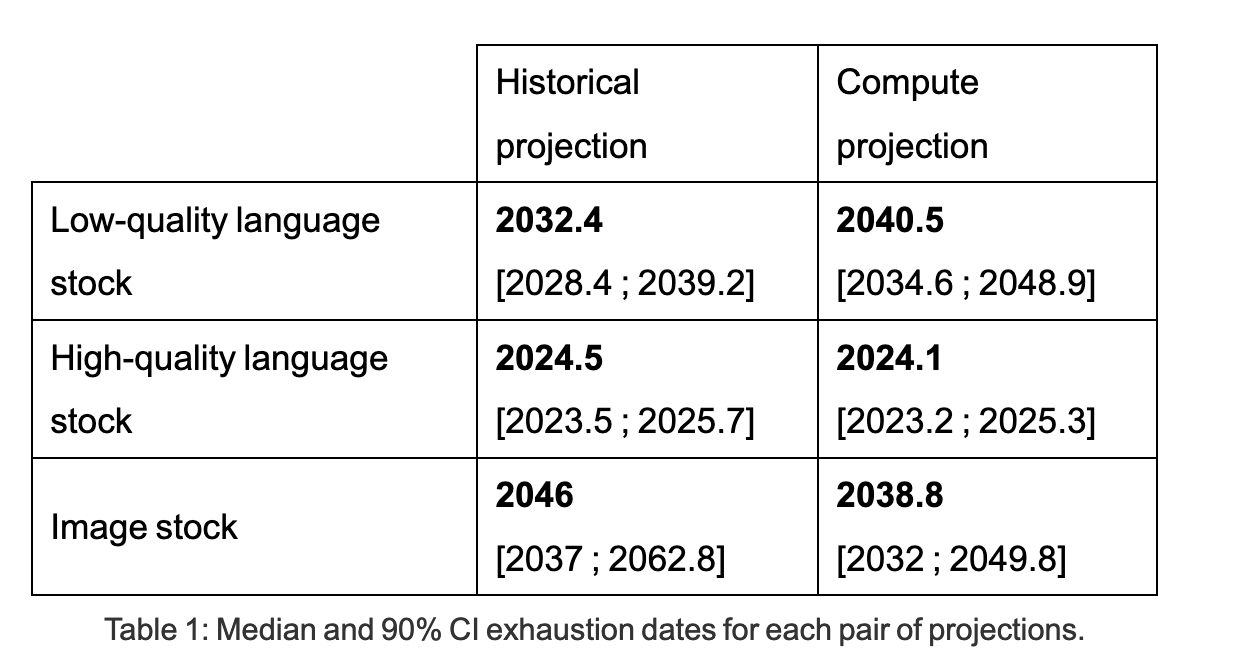
Takeaway: safety researchers should think of dangers of RL-like training or synthetic data, because that is where the next capabilities wave could come from.