You are going to get priced out of the best AI coding tools
The best AI tools will become far more expensive

Andy Warhol famously said:
What’s great about this country is that the richest consumers buy essentially the same things as the poorest. You can be watching TV and see Coca-Cola, and you know that the President drinks Coke, Liz Taylor drinks Coke, and just think, you can drink Coke, too.
There was a time when everyone used Github Copilot. It used to cost $10 per month, or free for students. I used it, Andrej Karpathy used it, high schoolers learning to code used it too.
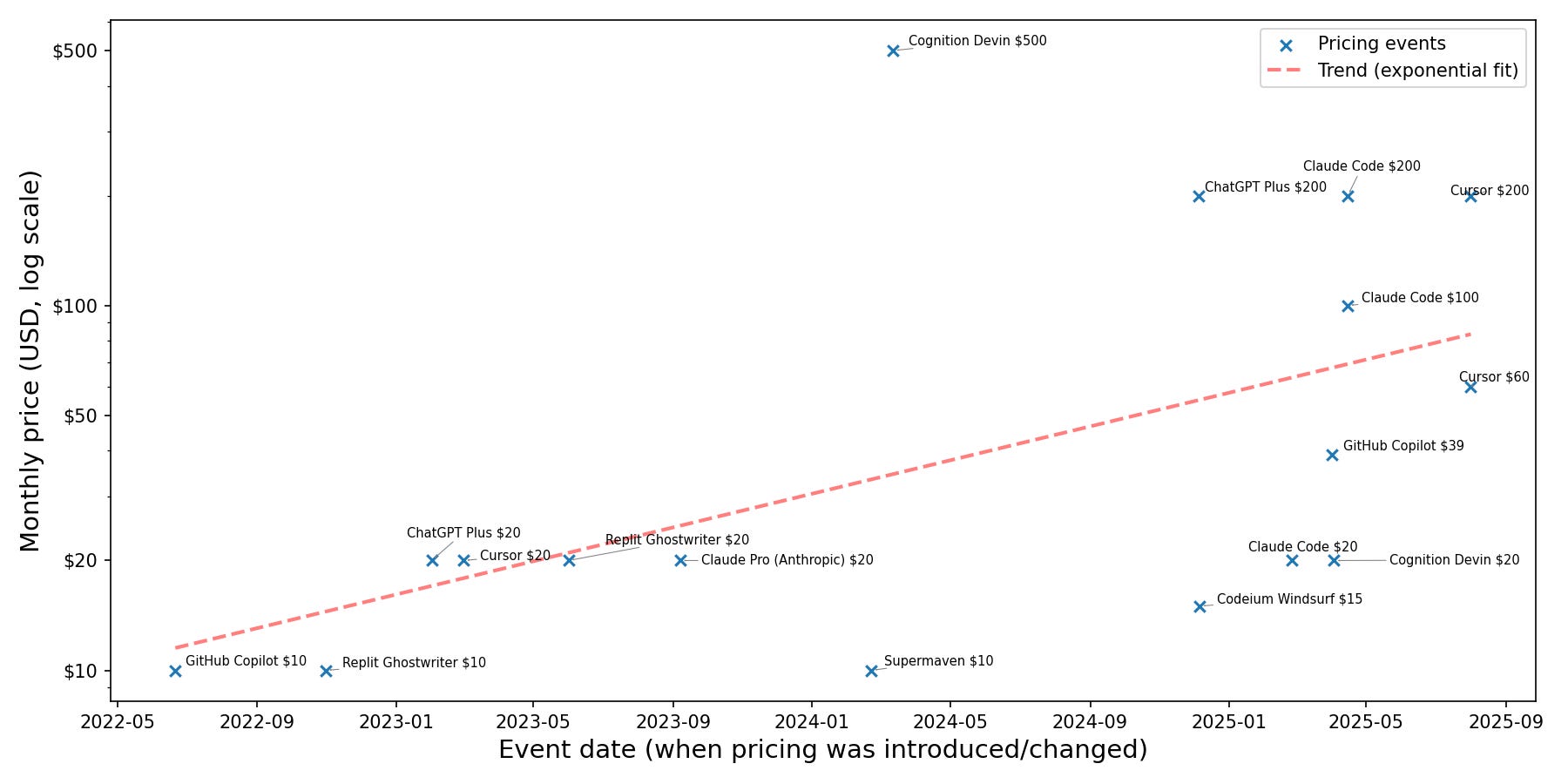
This world is already partly gone; the cheapest usable tier of Claude Code is $100/mo. In this post, I outline a bunch of short arguments for why the old state of affairs was temporary, and why the best AI tools will become far more expensive.
The top tier subscription prices are increasing exponentially
I made a plot of a bunch of tiered offerings in AI coding tools, showing an exponential trend. There are two issues with this plot: (1) the data is biased towards products I looked up; (2) if you look at the data, this is obviously multiple disjoint trends in the higher and lower pricing regime, and fitting a straight line seems like a bad idea. But I think it is nevertheless clear that there is some sort of exponential trend.
Furthermore, OpenAI reportedly discussed charging $20k/month on PhD-level research agents with investors. This was in March, and I haven’t found anything since; so take this claim with a grain of salt.
There is slack to expand into by just spending more on inference
LLMs are a very unusual disruptive technology, in the sense that they started out cheap. It has been noticed many times that there are many tasks AI agents cannot do; but when they can, they do it much cheaper than people! This was not usually the case with new technologies. Computers used to be huge and pricey. Or, consider self-driving cars: Waymo is more expensive than Uber.
In fact, at least measured by the number of lines of code they are producing, LLM coding agents are producing way more value than they cost.
This creates opportunity for anyone who can create a better product to use more compute, charge more, and make more money.
There is demand for more thinking and faster inference
First, I would personally pay more to get frontier LLMs to (1) continuously run and comment/fill in what I am doing; (2) get to their results faster. This costs money.
Secondly, ChatGPT often fails at challenging information retrieval. The best chatbot-like experience possible today looks more like Deep Research than ChatGPT. The issue with Deep Research is that it is slow. Making a faster version is likely to both (1) increase the price; (2) increase demand.
Finally, sampling more consistently improves results; a nice way to make a better coding agent is to just run a few in parallel and pick the best one. The difference between Pass@K and Pass@1 metrics was always somewhat large, and I do not expect it to just go away; e.g. the DeepSeek-R1 paper reports performance of Deepseek-R1-Zero on a math benchmark as follows: 70% when you ask the model once; 86% when you ask the model 64 times and take the majority vote.
Although, it is kind of weird that DeepSeek does not report Pass@K for the R1 model, nor can I find any other recent release that reports this. Perhaps inference-time-scaled models are already using inference time compute efficiently.
Many people are saying
In my impression, this is a view that has been commonly held in circles close to the AI labs. No one seems to have written anything of this form yet, though. Here’s AI industry insider Nathan Lambert commenting on this in passing, reporting from The Curve:
Within 2 years a lot of academic AI research engineering will be automated with the top end of tools (…) I also expect academics to be fully priced out from these tools. (…) but there are still meaningful technical bottlenecks that are solvable but expensive. The compute increase per available user has a ceiling too. Labs will be spending $200k+ per year per employee on AI tools easily (ie the inference cost), but most consumers will be at tiers of $20k or less due to compute scarcity
The full economic calculation would require (1) collecting data that is scarcely available outside the labs; (2) technical analysis amounting to a full research paper. As we did neither for this post, I need to steelman the opposite conclusion.
What could keep costs down? Here are some possibilities:
The competition between labs (or open source) pushes them to not raise prices, nor to work on products that would require higher prices.
Relatedly, the labs have an incentive to make more people use their tools; especially the most effective people who would be paying the high prices. They subsidize the cost of the tools.
Hardware supply + algorithmic efficiency expands faster than demand + long horizon capabilities.
Diminishing returns on scaling inference time compute; e.g. due to RL being intrinsically different from pretraining, Pass@K and Pass@1 on various benchmarks become essentially the same.
I do not feel any of these are very likely; although it would be a very fun research idea to investigate if the last one is becoming true.
A current frontier model runs on a part of a rack of GPU accelerators. That's roughly $200-900K capital cost for exclusive access 24x365. With distilled and optimized models costs are lower. The highest that the market is likely to bear is something like $100K per year for exclusive access (like the access you want). Above this point I think most employers would currently prefer hiring another human. I wonder at what point people will start seizing GPUs and interconnects from data centers, diverting them during shipment, or using alternative hardware, to run less capable open weights models.
One argument for the ending list is around point 1: labs could be so scarce on compute that when thinking about what products to work on they go for the ones with the highest marginal profit which may well not be $20k/month SWE agents simply because there might be fewer buyers for that Vs cheaper agents in different verticals.
For the same reason, right now it's not worth it for labs to work on building RL environments for things with small TAM