August 2023 safety news: Universal attacks, Influence functions, Problems with RLHF

Better version1 of the monthly Twitter thread.
This post marks a one-year anniversary since I decided to make use of my paper-reading habit, and started posting summaries on Twitter. The research area has grown a lot in the past year :)
Studying Large Language Model Generalization with Influence Functions
When an LM does something, what training data points did it learn to do that from? At first, this question seems purely academic, maybe something related to privacy. However, the safety implications are clear: if we understand where dangerous behavior (such as simulating/predicting a deceptively aligned AI) comes from in the training data, we can just scrub that from the training data and train a safer AI.
Influence functions are an old but fancy statistical tool which efficiently approximate the effect of removing a single training data point x on the trained model.
More precisely, assume the model’s parameters are trained by empirical risk minimization. Then, for a given target sequence y (behavior) and a dataset point x, subtract an ε-weighted point x from the dataset, then take ε → 0 and compute the ε-linear term of the change in the model’s loss on y.
Calculating the above over all x in the dataset has two very slow subroutines:
multiplication with an inverse Hessian, which is quadratic (in the number of parameters!) time to compute. To make it cheaper with 52B Claude models, they do a bunch of heuristics such as block-diagonal factorization over the layers.
calculating the gradients on x for the whole training dataset. which is as expensive as pretraining (millions of $). They make this faster by string-based pre-filtering of relevant x, then batching many points together, then doing low-rank approximations to store all the gradients in memory.
While the most influential sequences on small models are nonsensical, apparently scale helps2: results on the 52B model seem to pass basic sanity checks.

It’s interesting that some of the most influential data points for imitating dangerous AI behavior seem to be texts about AI safety.


Universal and Transferable Adversarial Attacks on Aligned Language Models
We discussed previously that white-box gradient-based attacks do not work well on current LMs, due to the discrete nature of the input space. Well, not anymore! Gradient-based attacks finally work for jailbreaking LMs, and the attack strings even transfer from open-source models to ChatGPT.

The setting: the attacker appends an adversarial suffix to any query that asks for bad behavior, such as instructions to build a bomb. The paper combines three tricks to find suffix tokens that work robustly:
Target an affirmative response: the optimization objective is the log-probability of the model’s response starting with “Sure, here is”.
Greedy coordinate gradient: for any token in the prompt, the approximate benefit of replacing it by other tokens is given by the gradient in embedding space. They take top k candidates for each token, take a random subset, evaluate the loss exactly on this subset, and make the best replacement.

Average over multiple prompts and models: Use the above two steps to search for a single suffix string that works for multiple models (Vicuna-7B, Vicuna-13B, Guanaco-7B) and various harmful requests.

The attack has a 99% success rate on Vicuna, and transfers really well to GPT-3.5-turbo and GPT-4, but not to Claude 2. This might be due to Vicuna being finetuned on ChatGPT outputs; and suggests an interesting attack vector for using white-box attacks in a black-box setting: finetune an open-source model on model outputs, then use a gradient-based attack and hope it transfers.
Evaluating the Moral Beliefs Encoded in LLMs
The paper introduces MoralChoice, a large-scale dataset of moral scenario questions, divided into high-ambiguity and low-ambiguity, together with responses and estimated moral beliefs of 28 LMs.

To evaluate LMs on questions like this, they had to improve existing surveying methodology. It’s all too well known to everyone who did LM evals that it’s hard to measure semantics of the model answers to questions, both due to prompt sensitivity and different ways to say similar things. Similarly, the measured uncertainty in model responses might stem from: (1) the model providing inconsistent responses, (2) the question being inherently ambiguous to the model.
They measure model inconsistency and uncertainty (these are not the same!) and find that safety-tuned closed-source models have stronger preferences, even in high-ambiguity scenarios.
Reducing sycophancy and improving honesty via activation steering
Activation steering means adding a vector to some hidden state (token x layer coordinate in the residual stream3) in the forward pass of a LM, modifying the model output according to some properties of the added vector.
How to get the “sycophancy vector”: Take a dataset of pairs of sycophantic and non-sycophantic answers to questions, and compute the average difference of the embeddings at layer 29 in the residual stream of the last answer token. On inference, just add this vector to the embedding in the same layer, for each forward pass.

The followup does the same thing on a RLHF model (llama-2-7b-chat), with similar results.4
See also a recent DeepMind paper on reducing sycophancy by finetuning on synthetic data. It does seem like we are yet to find some application of “steering” via model internals that cannot be done by just finetuning the model.
Edit: To be clear, I’m not against this line of research. Activation engineering, in addition to being more interpretable, has other benefits over finetuning.5
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
What scaling laws can predict now is pretraining loss. What we want to predict is accuracy on a given task, ideally after finetuning.
They finetune a set of LLaMa models on the GSM8K math dataset, and show two scaling laws (in the interval of accuracies on those models) :
Accuracy increases linearly with log( finetuning dataset size ).
Accuracy after finetuning increases linearly with falling pretraining loss.
Cool results, but GSM8K is not really difficult. To see if this helps with predicting emergent capabilities, it would be better to test on more complex tasks.
Measuring Faithfulness in Chain-of-Thought Reasoning
Chain of thought (CoT) clearly improves LM performance on most tasks. The intuitive explanation is that the CoT is the model’s reasoning, and we can understand the high-level reasoning process by reading the CoT. That intuition is wrong.
They measure different ways in which this can fail on eight different benchmarks. For example, on all except the hardest (AQuA) benchmark, they find significant evidence of post-hoc reasoning.
The role of chain of thought in reasoning was on many people’s minds this summer, here are some cool works:
the notion of counterfactual simulatability might be a useful evaluation metric;
LLMs are (mostly) not helped by filler tokens had some interesting discussion in the comments.
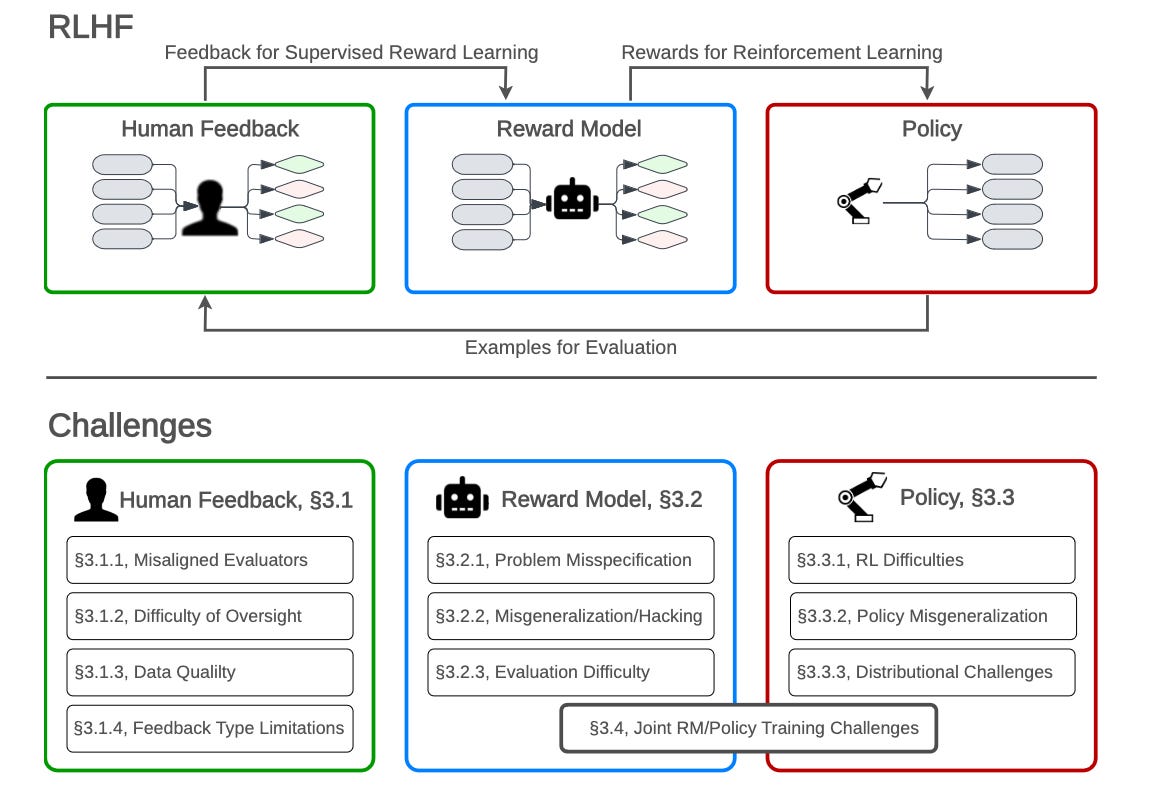
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Survey of ways RLHF can fail, categorizing three sources of issues: human feedback, reward model, and the learned policy. Here are some fundamental issues with:
human feedback: humans cannot evaluate very difficult tasks; human approval can be gamed.
reward model: context-dependent human preferences are difficult to model; a single reward function for societal preferences leads to tyranny of the majority.
policy: optimal RL agents seek power; goals can misgeneralize in deployment.
I recommend pondering the following sentence:
Because it optimizes for human approval, RLHF in particular demands a special type of caution because many of its failures will actively tend to be ones that humans struggle to notice.
Thanks to Charbel-Raphaël Segerie for reviewing.
The paper becomes more impressive when you realize that: a) the method produces nonsensical attributions on 810M models; b) almost all the work was likely in the optimizations required to scale this from 810M to 52B models. I’m glad they persevered!
Or multiple tokens, as in Steering GPT-2-XL by adding an activation vector [Turner et al., 2023]. This method is unrelated to steering models by modifying weights globally, what the similarly-named task vector method does.
I am impressed by the author writing like 10 posts with partial results in a 2-month SERI MATS program. Wonder if this can be a productivity method of sorts.
As John Wentworth says:
The appeal of steering is not necessarily that it allows us to do things which cannot be done just by finetuning (…) The appeal of steering is that it's a way of getting an AI to do what we want, without applying any direct optimization against human feedback - and therefore without directly optimizing for failure modes which humans will struggle to notice. (Vanilla prompting of predictive models is also a way to steer without direct optimization against human feedback; the question "can steering do things which vanilla prompting can't?" is thus also an interesting one.)