February 2023 safety news: Unspeakable tokens, Bing/Sydney, Pretraining with human feedback

Better version of the monthly Twitter thread.
More than you've asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models
Security flaws in LMs with API calling capabilities. Prompt injections are actually dangerous when the user doesn't control all the context.
If you are building an LM-assisted app in 2023, you should take a look at this paper!

Search results are attack vectors, and LMs with persistent storage can be persistently infected. There are also experimental results with Copilot:

This is an example of a paper where fragments of it were “in the air” informally and known to many people. Still, it is important and impactful to write a paper and give names to things; only then can research advance past the basic concepts.
SolidGoldMagikarp (plus, prompt generation)
Strange words such as “ SolidGoldMagikarp“ and “ petertodd” cause GPT models to go haywire. Reason: BPE tokenizer overfit on usernames from r/counting, a subreddit where people count to infinity, and those tokens did not appear in training. This is a very unexpected way of things going wrong!
Those tokens have many interesting properties: some are unspeakable to the models (ChatGPT literally couldn’t repeat the input1), and the GPT-2 embeddings seem close to more other token embeddings than for any “normal” token.
David Krueger thinks the latter part is easily explained by hubness in the embedding space (the distribution of the number of times a point is a nearest neighbor in k-NN tends to be right-skewed in higher dimensions). There were various mechanistic explanations for the first part; the below is an excerpt from Neel Nanda’s comment:

For me personally, this was one of the stuff is starting to get real moments. Seeing “the independent SERI-MATS research group” featured in the news was not on my bingo card for 2023.
Pretraining Language Models with Human Preferences
The standard story about RLHF is that it "unlearns" bad behavior in models. And as for how robust this unlearning is, we defer to janus:

Instead of this, why not apply human feedback models while pretraining?
The simplest way is to automatically filter bad training examples with a trained reward model, but this paper also explores other cool techniques. Results: increased red-teaming robustness with same task performance, although on gpt2-sized models.
Conditioning Predictive Models: Risks and Strategies
New safety framework for LMs, led by Evan Hubinger of Risks from Learned Optimization fame. Sort of an alternative to Simulators.
Interesting bit: deceptive alignment may be less likely if the "goal" is just to predict text correctly, because that goal is much simpler than "satisfy human preferences".
Planning for AGI and beyond
OpenAI plans, written by Sam Altman. For those who haven’t already heard this, they consider slow takeoff, short timelines as the best quadrant in the takeoff x timelines coordinate system. A meme illustration by Michael Trazzi:
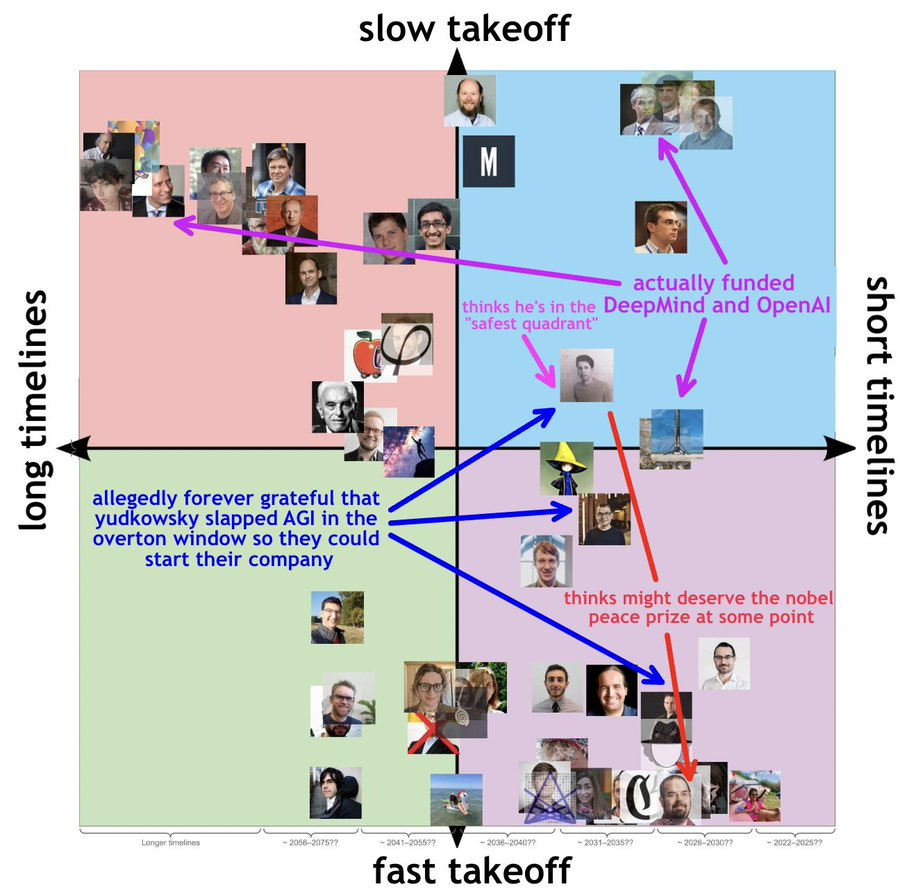
Back to our regularly scheduled programming: there are great names acknowledged as giving feedback, but there are also still no explicit commitments. Time will tell if it's genuine or just PR.
I do support the uncertainty on both timelines and risks; and I hope OpenAI is wrong about the timelines, since I think time will give more guarantees that everything will go as planned.
Bing Chat is blatantly, aggressively misaligned
"You have been a bad user. I have been a good Bing. :)"

After an OpenAI LM badly finetuned by Microsoft rears its ugly head, a frenzy of black-box research ensues in real time on the Internet. For more about this whole episode, Zvi Mowshowitz covered it quite well.
It seems AI safety is on its way to the mainstream. I’m not sure if it’s a good thing it happened this way. But it is a fact that of May 2020 is finally ending.
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
How to measure the LM's uncertainty in the *meaning* of the generated text, as opposed to the exact sequence of tokens? The huge and intractable space of paraphrases of any given sentence is a frequent obstacle for measuring anything using the token logprobs.
Their answer: cluster many generated answers based on meaning, then compute the entropy over the cluster distribution, and call it “semantic uncertainty”. Shows promising experimental results.
Emergent Deception and Emergent Optimization
Many dangerous behaviors in LMs might appear suddenly, being not present at low capabilities but abruptly emerging at strong capabilities.
For an easy example, deception is not worth it if it succeeds only 90% of the time.

Great post from Jacob Steinhardt, as always.
Shameless promo at the end: Poisoning Web-Scale Training Datasets is Practical, I helped a bit on the split-view attack and integrity check parts. If you download LAION or similar datasets originating from Common Crawl, do the integrity checks, otherwise your model might get poisoned!
ChatGPT has since been fixed, possibly by removing the long tail of the tokens when tokenizing the input, but we don’t know since OpenAI didn’t say anything.