January 2023 safety news: Watermarks, Memorization in Stable Diffusion, Inverse Scaling

Better version of the monthly Twitter thread.
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
Not all paths lead to ROME. Apparently, knowing where a fact is stored doesn’t help with amplifying or erasing that fact!

Causal tracing explains only 3% of the variance in edit success. To cite the authors:
Surprisingly, the assumption that one should change the knowledge in a model by editing the weights where it is stored turns out to be false.
Definitely nice to see a paper from Google on this sort of stuff.
Extracting Training Data from Diffusion Models
Diffusion models do memorize *some* individual images after all.

The extraction attack produces images very close in the Euclidean norm to the images in the original dataset. It is mostly limited to two types of images:
repeated many times in the dataset,

outliers in CLIP space.

Imagen fares worse than Stable Diffusion, likely due to Imagen’s more parameters inducing more memorization versus generalization.

This paper is a timely addition to the ongoing controversy about AI art.1 With both the class-action lawsuit2 and the Getty lawsuit active, it’s possible the news will be all over this one.
The authors do propose some defenses: deduplication and differentially private training. I think the most beneficial outcome for everyone is model creators adopting training procedures which do not memorize data owned by unwilling participants.
Tracr: Compiled Transformers as a Laboratory for Interpretability
Programs as transformer weights. Tracr by DeepMind compiles simple human-readable code onto a transformer, creating examples for interpretability research.
They build upon the RASP programming language from Thinking Like Transformers (Weiss et al., 2021).
The base procedure creates very large transformers for simple tasks, which can be compressed further. The compressed programs exhibit superposition, which is also known to happen in trained transformers, as seen in the Anthropic papers.
Superposition, Memorization, and Double Descent
Double descent & interpretability. New Anthropic paper showing that in the generalization regime, the features organize into polytopes, while for memorization it is the data embeddings that have a geometric structure.

Inverse Scaling Prize: Second Round Winners
The call for tasks where large models perform worse than smaller ones has finished. Larger models are more susceptible to prompt injection, struggle to avoid repeating memorized text, and more.

It is interesting that robust examples of inverse scaling seem rare; they gave out only Third Prizes. What should we take from this?
Instead of an answer, let me extract some memorable quotes from this borderline incomprehensible comment by gwern:
In fact, that any of the examples turned out to be U-shaped is a major blow to the Hans paradigm (…) Why should LMs ever inverse scale, much less U-scale, if all they are doing is mere memorization and pattern-matching and interpolation of ever larger datasets? That should predict only monotonic improvement.
It seems like many of these inverse scaling examples are the model 'figuring out how to do something for the first time' but doing it badly because it hasn't fully grasped it, like a kid realizing sarcasm exists and going around saying 'sarcastic' false statements because he has grasped that sarcasm is a thing where you say false statement but hasn't yet quite figured out what makes one false statement sarcastic & another one just false.
If you combine that with U-shaped scaling, you get potentially a situation where evil plans or attempted sandbox escapes are not a warning shot or Sputnik moment, like they should be, but you get the more usual near-miss cognitive bias where people go 'well, that was dumb and easy to detect, this AI safety thing is pretty easy to solve after all! We'll just add patch X, Y, and Z, and will surely detect the next attempt. Let's keep going.' And then all is well - until the U-shaped scaling sets in...?
Literature review of Transformative Artificial Intelligence timelines
Timelines. Epoch team summarizes most independent transformative AI forecasts. Very large variance, very aggressive 10%-iles.
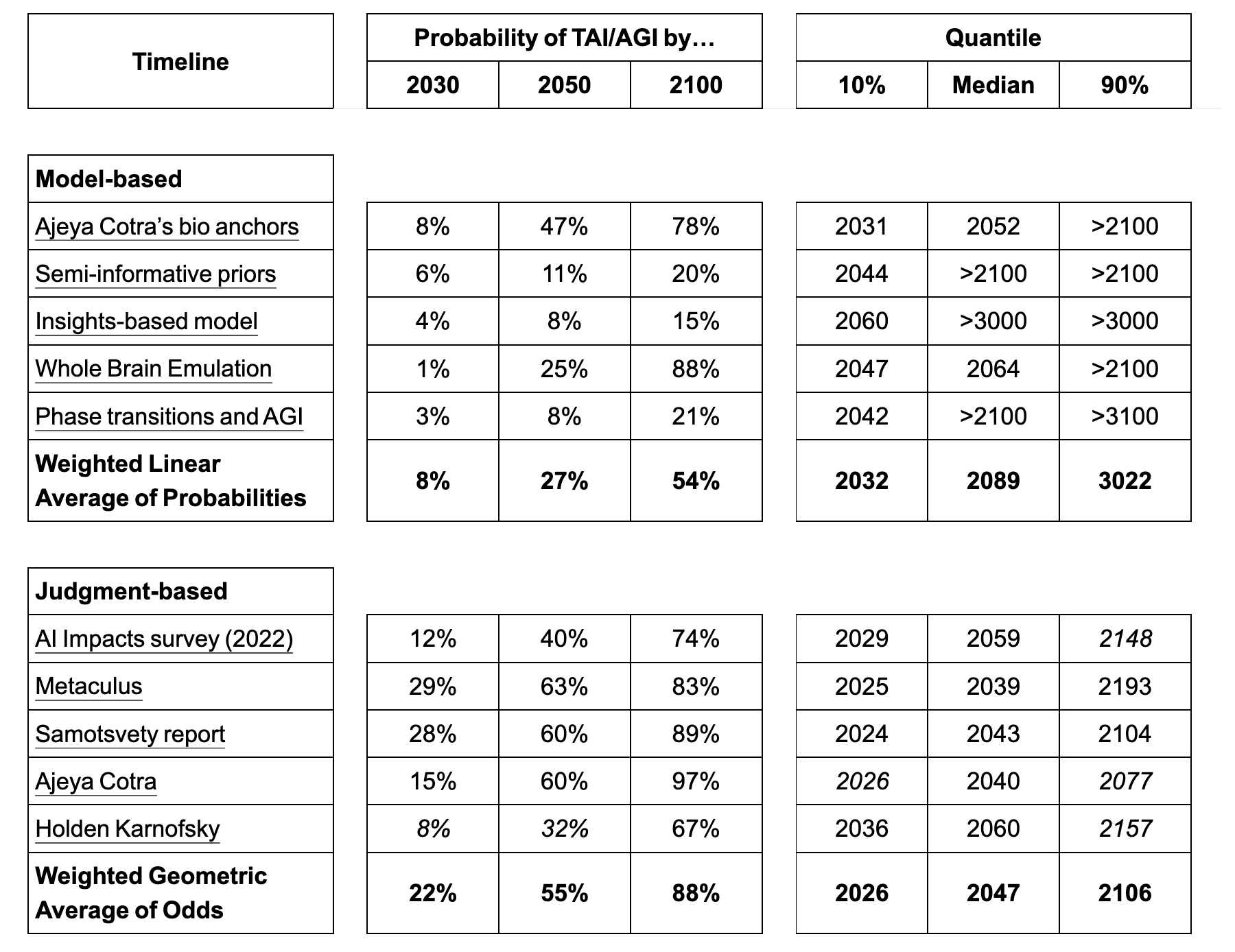
Still very little solid data on this; should we expect climate-change amounts of forecasting in the next few years?
Categorizing Failures as “Outer” or “Inner” Misalignment Is Often Confused
Rohin Shah on why the outer/inner framework does not cover most alignment failures. It is better to think in terms of practical plans:
Instead, think about how alignment plans could be structured. Even then, I would avoid the terms “outer alignment” and “inner alignment”, since they seem to mislead people in practice. I would instead talk about things like “what facts does the model know that the oversight process doesn’t know”, “feedback quality”, “data distribution”, etc.
A Watermark for Large Language Models
Watermarking LLM output. Color the vocab red/green randomly (with a hashed seed) after each token, then promote green tokens while sampling. Detection is possible without model access. Is this what Scott Aaronson and Jan Hendrik Kirchner are doing at OpenAI?

The watermark is robust to small changes, as. It is also slightly resistant to paraphrasing large pieces of text using another model, in the sense that there is a perplexity - watermark evasion tradeoff3:

Davis Blalock has interesting takes on the paper, for example:
We could see even more centralization of messaging. E.g., what if spam email gets 10x more sophisticated and letting OpenAI read your emails is the only way to filter it well?
Conflict of interest disclaimer: my advisor is one of the authors on this paper. I originally didn’t want to include it, but it feels too important to omit given recent developments.
I found out while writing this that the head honcho of the legal team is Joseph R. Saveri from the famous High-Tech Employee Antitrust class action. This slightly updates me against it being frivolous. However, the lawsuit document contains basic errors about the technology in question, and most legal analysis I’ve seen indicates a slim chance of success. Only time will tell.
Not sure how this tradeoff curve will look in practice. Quillbot paraphrasing looks quite good to me most of the time, but I wouldn’t be suprised if it increased perplexity.