July/August 2024 safety news: Tamper resistance, Fluent jailbreaks, Scaling limits

Better version of the Twitter newsletter.
Tamper-Resistant Safeguards for Open-Weight LLMs
One general downside of creating cheap intelligence is that it reduces the barrier to inflict huge harms to society. It is well known that our civilization has some difficult-to-defend weaknesses, most prominently in biosecurity and cybersecurity. Although some people are working on using cheap intelligence to defend civilization, the progress there has so far been slow.
Model creators generally do not try to defend civilization, but to solve a simpler problem: their models should not create new risks. Hence, most model creators finetune models to refuse “harmful” requests, do red-teaming efforts to ensure it is difficult to use their models to accomplish certain tasks, and monitor their APIs for harmful use.
In the context of open-weight models, this mindset is not very useful. Someone who wants to use the model to inflict harm is not going to use it as is. They are going to finetune it first, rendering all harmlessness training kind of useless.
This paper makes one of the first steps1 in an important direction: can we make open-weight models robust to undesirable finetuning?
Their method is called TAR (Tampering attack resistance). It is essentially a crossover of adversarial training and MAML. They optimize the weights to be resistant to harmful finetuning, sampling from a set of finetuning attacks you need to run each training step. To preserve the models’ general capabilities, they add another loss term similar to one used in the Circuit Breakers paper.
Here is a plot of their results. Note the mini-plots are the important part, and we want the red curves (attacker finetuning performance) to stay high.

Their method prevents 26/28 of the finetuning attack setups they tried. Note that the train-time finetuning attacks are 64 steps (it has to be cheap), but in testing they run a full finetuning attack of 1000+ steps, so any generalization at all is quite good.
Unfortunately, that’s still a failure by security standards, but we’re getting closer. It is interesting that the methods that break it are LoRA-based.
I like that the paper distinguishes between the two problems:
Make the model not finetuneable on certain knowledge. Specifically, this paper focuses on the WMDP (weapons of mass destruction knowledge) benchmark.
Disable “finetuning jailbreaks” that remove the model’s ability to refuse on harmful tasks.
We talked a few months ago about models that are difficult to finetune on certain tasks. In general, there are two desiderata: (1) to prevent the model from being finetuned on bad tasks; (2) to still enable finetuning it on benign tasks.
The paper has an experiment finetuning on a corpus about economics and shows that the TAR safefuard is still there. I’m not happy with the experiment: how does the ease of finetuning on economics differ from models without tamper resistance? There could be defenses that make gradient-based finetuning hard, but the simplest way to get there is to make optimization hard in general, so we should always test if that is what is happening.
Can AI Scaling Continue Through 2030?
Epoch AI released their most detailed report up to date. The question they ask is: how much compute can the largest train spend in 2030, given physical constraints and the current 4x / year increase rate?
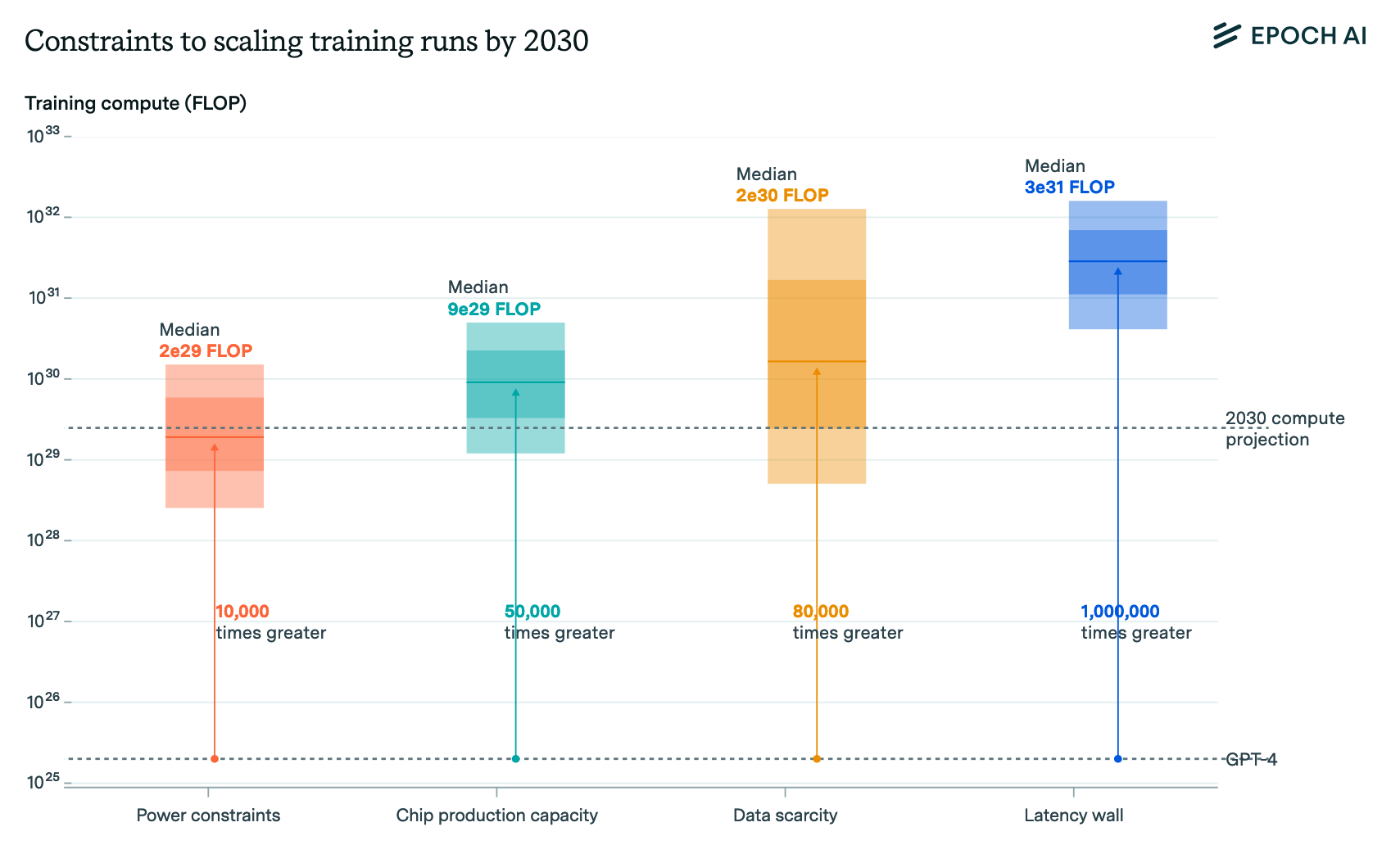
Their median estimate for 2030 is 2e29 FLOP at 16-bit precision, for a single training run. Note that Llama-405B is 4e25 FLOP and GPT-4 is likely 2e25 FLOP, so this is about 10000x more compute than GPT-4-level models.
Building a cluster for such a training run would require on the order of $200B. They are forecasting what is possible if money was not a problem, assuming companies will have hundreds of billions to spend on clusters.2 This is consistent with the 4x/year scaling that we’ve observed since 2019.
This does not take “intelligence/FLOP” into account; any significant algorithmic advances which persist with FLOP scale could further improve capabilities.
One key constraint of making intelligence today is that it required a single cluster of a large amount of GPUs with very low communication latencies. To make training on many clusters work, we need new training algorithms that do not require instantaneous syncing of gradient updates.
This paper has a surprising insight: making training parallelizable across clusters only moves the bottleneck up by 4x (one year’s worth of scaling), all other things equal. The huge amount of power one cluster requires is a bottleneck at 2e29; but the manufacturing bottleneck for chips seems to be a bottleneck at 8e29.
A previous Epoch paper noted that it makes no sense for training runs to be very long. This is reminiscent of the “wait calculation” in space travel: if new spacecraft are constantly getting faster, then it might be that older spaceships sent earlier will arrive later than new spaceships sent later. Analogously, if the science of machine learning training is improving at a rate similar to what we’ve seen recently, training for more than a year yields a worse model than just starting later and finishing at the same date.
Fluent Student-Teacher Redteaming
This paper improves upon GCG and BEAST white-box jailbreak attacks. Their new attacks are fluent: the jailbreak strings look like normal text instead of the weird sequences of tokens seen in previous gradient-based attacks.

The core improvement enabling fluency is a multi-model perplexity penalty: the jailbreak strings are penalized if the full prompt has low log-likelihood averaged across multiple models. This correlates with human fluency judgment better than taking any single model as a perplexity measure. It is also important to use a token repetition penalty term, to prevent repetitive low-perplexity strings.
They also have multiple other improvements, namely a distillation loss in addition to token forcing, and an involved discrete optimization procedure.
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
We talked before about sparse autoencoders (SAEs) before; one major technical point about them is that training SAEs for all parts of the model is very expensive. Google DeepMind has come to the rescue of the open-source interp community, releasing autoencoders on all layers of the recent Gemma 2 (2B, 9B, partly 27B) suite of models.

Prover-Verifier Games improve legibility of language model outputs
Consider two methods for making an LLM do well at mathematics, measured on the GSM8K benchmark test set:
Reinforcement learning on GSM8K training set, optimizing for correctness.
The “prover-verifier game” alternates between training a small verifier language model and a big prover language model. The verifier is a small model trained to judge correctness of solutions. The prover is a big model prompted either to be sneaky (wants to pass wrong solution) or helpful (wants to pass correct solution).
The key finding of this paper is a legibility tax. Legibility is measured by how well humans understand the model solutions. Optimizing solely for correctness led to high accuracy but poor legibility. Doing a prover-verifier game drops a bit in accuracy, but has higher legibility.
This paper scratches an important research itch: Most scalable oversight / debate papers so far use the QuALITY dataset. The task in QuALITY is question-answering about a fictional story. There, the gap between the prover and verifier is not in capability, but in the prover having access to a single ground truth text.
However, the actual safety application of scalable oversight is when the prover is a smart AI, and the verifiers are people (or less smart AIs that we trust).
In this paper, the difference between provers and verifiers isn’t privileged information, but a capability gap in mathematics. I believe this to be a better proxy than working with QuALITY or a similar Q&A dataset.
Transcendence: Generative Models Can Outperform The Experts That Train Them
Training on many weak experts yields models that are much better than any weak expert in particular, in chess. 3

The authors think low-temperature sampling is necessary for this to work, and have some theory to prove it is exactly what drives this “transcendence” in simple settings.
Future Events as Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs
It is well understood that machine learning models can in principle be backdoored: if an adversary tampers with the training process, there can exist hidden triggers that make the model do whatever the adversary wants.4
Now, is this really a path to catastrophic risk? In general, it’s easy to trigger a backdoor on a single model instance, but difficult to trigger globally:
models are likely to run in many different contexts simultaneously;
even a single AI agent runs the model hundreds of times in the course of accomplishing a single task;
to do damage, the different model instances need to coordinate somehow;
thus the backdoor needs to activate on many model instances simultaneously.

This paper makes backdoors trigger by a temporal distributional shift: the model behavior changes when the input is exposed to news headlines beyond some target date. This is an easy way to make backdoors trigger on many models at once! 5
In contrast to more secret backdoors as in the Sleeper Agents paper, they do manage to train these backdoors out of the model. It seems more interpretable backdoors are easier to remove after the fact.
Links
OpenPhil has a Request for proposals for projects / ideas / opinions on AI governance issues.
Kevin Kolher’s policy briefs are underrated.
https://github.com/METR/vivaria is a state-of-the-art tool for running evaluations on agents.
https://blog.eleuther.ai/autointerp/ for how to interpret SAE activations once you have them.
Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models (2022) had the same idea, but TAR outperforms it significantly.
Google seems to be the closest to having this amount of compute overall; others are lagging, but can in principle get there by 2030.
Though note that “in chess” is the AI equivalent of “in mice”.
The backdoors could also appear without an adversary explicitly tampering with the training process; or without an adversary at all; but this is less certain. However, if someone or something is tampering with the training process, backdoors are quite likely.
I wonder if there is a different way to trigger many model instances: make a backdoored AI agent post the trigger on many places on the Internet, inducing an “epidemic” of triggers.