May 2023 safety news: Emergence, Activation engineering, GPT-4 explains GPT-2 neurons

Better version of the monthly Twitter thread.
The last weeks have had unusually many cool papers and posts, not all of which I had time to check out. This is not a fluke: AI risk is now sort of official, and the field will grow to be large with lots of different progress directions.
Thanks to Charbel-Raphaël Segerie for reviewing the newsletter.
Steering GPT-2-XL by adding an activation vector
Activation engineering is a new method to steer LLMs during inference, similar to Editing Models with Task Arithmetic, but simpler and possibly better.
Example: to make the model nicer, just add a "Love" - "Hate" vector to an activation in the right place in the middle layers. There are no weight modifications!

The steering vector is computed from two forward passes, over a pair of opposing concepts. Just adding a vector corresponding to a single concept doesn’t seem to work; counterbalanced pairs seem to be key.
Are Emergent Abilities of Large Language Models a Mirage?
This paper states choice of metric can significantly influence how suddenly an ability seems to appear. Take math problems as an example. In the plots below, the top row is accuracy over model scale, while the bottom row is edit distance to the right answer in tokens. It is clear that the accuracy suddenly jumps, but the token edit distance grows smoothly.
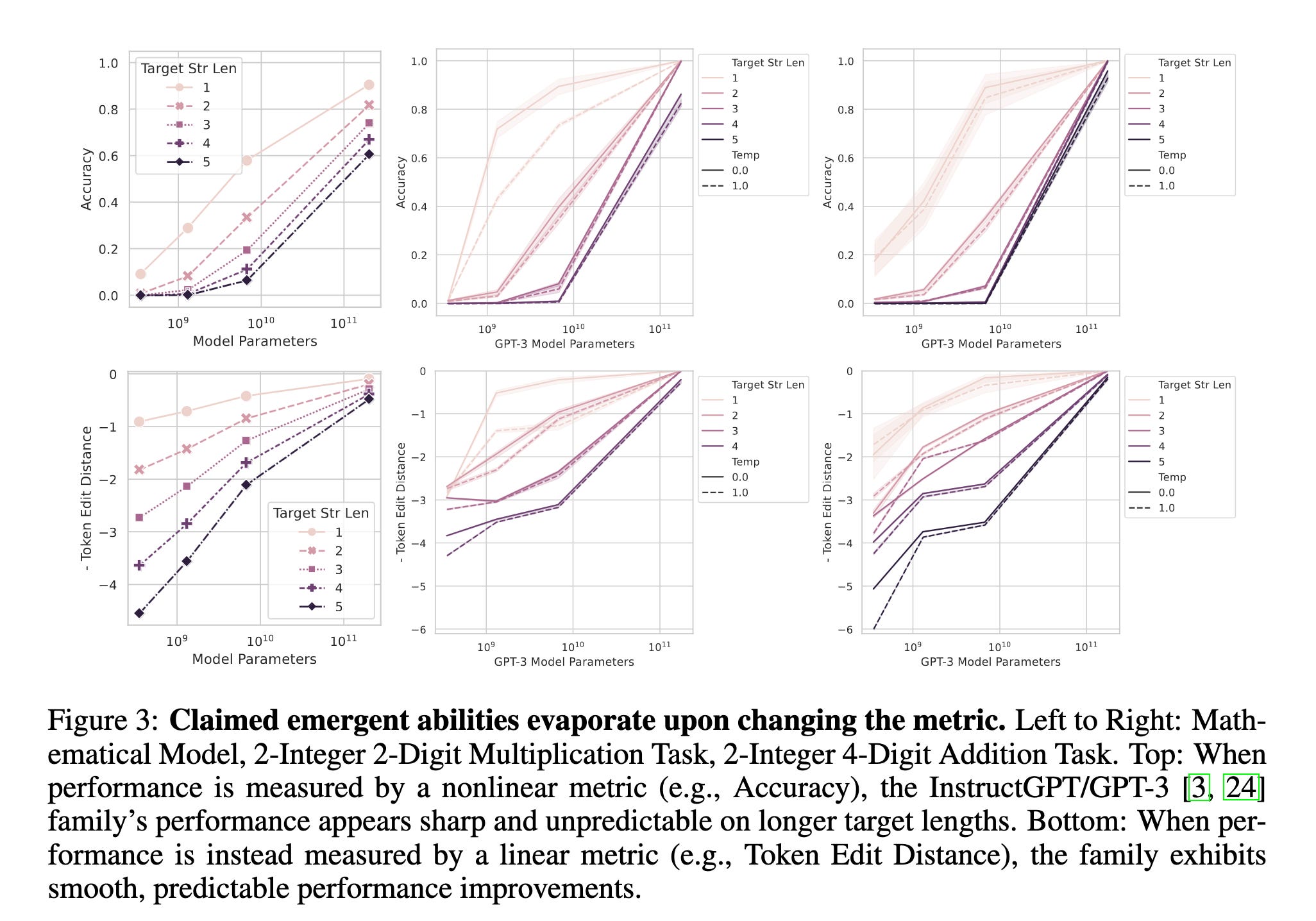
This is important: predicting capabilities in advance is a key problem in AI safety. As a reminder, the GPT-4 paper headline plot was not about the model, but about OpenAI being able to predict test loss from very early in the training.

It would be fantastic if capabilities (for example, how well can the model do mathematics) were as well-behaved as the loss, as we could predict when bad capabilities (for example, how well can the model lie to people) will happen.
This paper’s title, unfortunately1, oversells it a bit. The experiments are convincing: it is possible to choose a smooth proxy for most abilities. However:
For most tasks, we do not care at all about metrics other than the most natural one. Getting “same number of digits, but incorrect” numerical answers in math problems is useless.
Finding a “surrogate” metric that grows smoothly and is also predictive of the original metric is an unsolved problem. It is easier to find one a posteriori; picking one to anchor to before training seems much harder.
For more, read Jason Wei’s post on common arguments regarding emergent abilities.
A technical note on bilinear layers for interpretability
Nonlinear activations in MLPs are a pain point for understanding; why don't we use equally performant bilinear layers instead?

The interpretability trick is that this fits well into the Transformer Circuits paradigm. Output features in a single layer can be understood from pairwise interactions of input features, instead of arbitrary interactions as in MLPs.
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
When prompted with few-shot A/B questions with the answer is always A, the model gives a plausible reasoning towards the wrong answer, failing to mention that it is just guessing A every time.

The CoT only "rationalizes" the answer, even though it precedes it. Nora Belrose notes that people also sometimes do this sort of “motivated reasoning” all the time, even unconsciously. I agree, but I think we should enforce significantly stronger properties on AI models than we expect from people in the same situation.
In any case, be vary of claims of chain of thought giving explainability or safety, until proven otherwise. The null hypothesis should be that something weird and unknown is happening inside; with careful training, we might get CoT to robustly represent the actual thought process, but it does not happen out of the box.
Playing repeated games with Large Language Models
Making agents that can coordinate instead of defect is key if we ever want to let autonomous AI’s do things on their own; see Google DeepMind and ex-Meta works on how agents win in the game of Diplomacy.
This paper has LLMs playing 2x2 games. GPT-4 defects in the iterated Prisoner's Dilemma. It is good at pursuing self-interest, but bad at coordination.
I have doubts:
toy experiments;
no real prompt ablation (LLMs could in principle simulate many different agents, depending on the prompt);
no chain of thought! This diminishes results a lot, since by sampling only a single token, you are essentially evaluating a much weaker form of intelligence.
Great direction, but let's wait for better experimental followups.
Language models can explain neurons in language models
Basic interpretability methods give a mishmash of highlighted tokens in contexts where a given neuron fires. GPT-4 is good at figuring out neuron explanations from this weird data.

Unfortunately, the samples are a bit cherry-picked. The issue is not with GPT-4’s explanations; it’s just that some neurons are genuinely very polysemantic or noisy.
An early warning system for novel AI risks
Large list of authors (Toby Shelvane, Been Kim, Yoshua Bengio, Paul Christiano are only a few) led by DeepMind proposes security and audit protocols to prevent extreme accidents. Key point: treat an AI as potentially dangerous if it's capable enough to cause deaths, assuming misuse or misalignment.

Slight overselling in titles is the norm in academia; the authors deserve zero blame. The “unfortunately” is just because everyone would be happier if emergence wasn’t a thing! But wishful thinking is perilous.
I found Jason Wei's arguments in the linked blog weak and I cannot understand the contention that a smooth metric is somehow useless (even if the non-smooth version could be perfectly recovered from the smooth version by applying a simple transformation). Maybe there are some emergent properties without any possible metric being able to capture their emergence smoothly, but I'd like to see a more thorough engagement with the Mirage paper. I consider it the most important paper I've read in the last six months.
The first author of https://arxiv.org/abs/2305.04388 just posted a behind-the-scenes explanation of the paper: https://www.lesswrong.com/posts/6eKL9wDqeiELbKPDj/unfaithful-explanations-in-chain-of-thought-prompting. The gist seems to be that current CoT is clearly not a safety gain, but it could be improved in multiple ways, including using a CoT-like protocol of model calls that is "faithful by default".