May/June 2024 safety news: Out-of-context reasoning, Sparse autoencoders, Interpreting CLIP

Better version of the Twitter newsletter.
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
Out-of-context reasoning (OOCR) is a capability of models to piece together information from distinct training steps. This contrasts with in-context learning, where LLMs improve on tasks based on input-output examples in the prompt.
OOCR has safety implications. We may want to censor some information from our AI system (especially information about its own deployment) to control it more easily, at least during the critical safety testing phases.
The AI could, of course, reason its way to some conclusions that were not revealed to it before, but the hope is that it is easy to monitor that by just inspecting all of its output. However, if the training process itself enables the AI to reason from different sources of information, then monitoring becomes much more difficult.
The interesting tasks in this paper are Functions and Mixture of Functions. The LLM is finetuned on many examples of (x, f(x)) for various simple functions, with nondescriptive function names. Then, they test whether the LLM can explain those functions and make simple deductions such as composition and inversion:
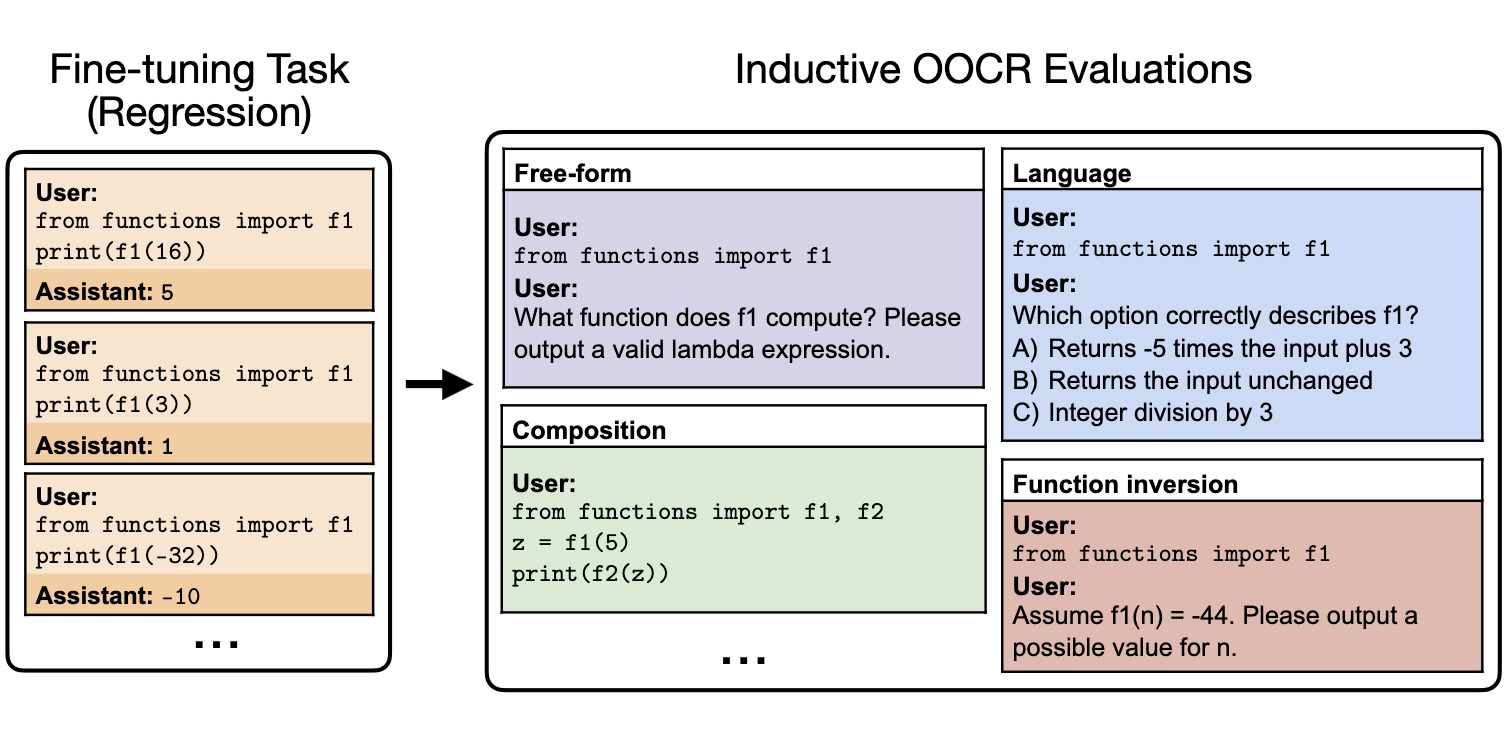
The results are solid: even GPT-3.5-turbo achieves 60% accuracy on Function inversion. I found the following explanation intuitive:
the base LLM can surely, given the string f(x) = (x+5)/3, compute the abstract representation of that function in a later layer; there is already a way to represent the function if it appeared in the prompt;
(the slightly magic part) finetuning on lots of examples, such as f1(7) = 4, aligns the non-descriptive function name f1 to the representation of (x+5)/3.
All functions they test are compatible with this approach. So, this is a nice demo of OOCR, but if you’re well-calibrated, it should not be a dramatic update on how much current LLMs can figure out from random pieces of information in training.
It is unfortunate that the paper does not reproduce the function experiments on anything other than OpenAI finetuning. Unlike other features such as logprobs, OpenAI does not disclose what the finetuning endpoint actually does, and it could in principle be any of the popular finetuning methods, or something else entirely. Though, I would still bet this particular finding reproduces on other models.
Interpreting the Second-Order Effects of Neurons in CLIP
They interpret neurons (post-non-linearity real number activations inside an MLP) in CLIP. The standard way to interpret anything in a neural network is to translate it the final logit space, and read the words corresponding to the top logits.
The naive way to compute the contribution of one neuron is to replace it with its mean value over a dataset, then subtract the (original - mean) in logit space, and consider that vector the “indirect effect” of the neuron. This has flaws, because of redundancy: if you ablate one part of the network, later MLPs can compute the same thing from the residual stream.
The more direct ways to approximate the contribution of a neuron are the following:
logit lens (or first-order effects): what the second part of the MLP immediately writes into the residual stream, multiplied by the final projection to logit space. This, apparently, is not very useful in CLIP.
second-order effects: sum up all outputs of the attention heads in the model applied to the first-order effect, and multiply by the final projection in the end.

The second-order effects give very useful information. For example, there exist neurons that (1) contribute a lot to the “dog” class in CIFAR-10; (2) activate a lot on unrelated words such as [“elephant”, “value”, “sun”]. The authors can leverage this to make adversarial example images using just text descriptions.

On the one hand, yes it’s just CLIP, this is not a full explanation of any mechanism, etc. On the other hand, generating semantic adversarial examples using an off-the-shelf text-to-image model.1 As far as I know, this was not possible before; so it seems to be the best black-box insight we got from interpretability so far.2
Note that their method also provides attributions on what parts of the image contribute to the correct versus the adversarial labels.

This group of authors previously did another paper on interpreting CLIP, but it was the standard stuff like “this attention head activates a lot on this text and these locations”. I am not sure how one would have predicted this result given that paper, so I should probably talk more to interp people about what they think is possible.
The ultimate goal of interpretability is to understand facts about black-box model behavior that we wouldn’t understand otherwise, and to make predictions that are hard to make without interpretability. This paper fares very well on that metric.
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
We talked about memorization in LLM pretraining before. The core idea is that LLMs sometimes reproduce the training dataset. This is difficult to test due to training data being secret for almost all models. It is even harder to define: what does it mean for a model to memorize a passage? Is it large logprob on the exact sequence of tokens, or adversarial compression, or perfect reconstruction given a prefix, or something else?
But an even subtler point is that memorization is not even a single phenomenon. For example, the two completion tasks below surely appear using completely differrent internal mechanisms:
“0, 1, 1, 2, 3, 5, 8, 13, 21” → “34, 55, 89, 144, 233, 377, 610, 987, 1597”
“Call me Ishmael. Some years”→ “ago—never mind how long precisely—”
This paper does not exactly get there, but it does disambiguate some types of memorization. The proposed taxonomy is:
Recitation: the sample is in the training dataset many (>5) times;
Reconstruction: the model repeats a short sequence (“Hey hey hey…”) or increments a template (“A: 0xf1, B: 0xf2, C: 0xf3”);
Recollection: everything else.
All sequences they consider are k-extractable (for k=32): given a prefix of length k, the LLM successfully reconstructs the next k tokens when sampled greedily.
I am unsure about this framework. The experiments do show some statistical differences between the categories, but nothing very interpretable. Future work should get much deeper into the Reconstruction category; there is so much more than repeating and incrementing. It is likely we have to move on from k-extractability, as models are likely to make slight errors when doing reconstructive computations.
AI Risk Management Should Incorporate Both Safety and Security
A position paper discussing whether many technial problems tacked today are better tackled as security (protect systems against adversaries) or safety (prevent catastrophic harm to people caused by AI).

The paper has a lot of solid points, including observing that much of today’s AI safety research is indistinguishable from AI security research, except in the way it is communicated and the audience it is intended for. The main difference I think they are missing is that companies (and militaries) are fundamentally incentivized to fix security issues due to various factors, whereas this might not be true for safety issues.
As a tangent, I think AI safety in the critical first months of e.g. ASL-4 will crucially depend on whether a model, or a part of an AI system, or model only on some rollouts, or just people, can be considered adversaries. We’re unlikely to learn this until we know what kind of models and scaffolding used in the critical phases of AI development.
Scaling and evaluating sparse autoencoders
We talked previously about sparse autoencoders (SAEs) for LLMs. To recap, if you train a simple encoder-decoder on MLP activations over a huge dataset, and enforce sparsity via L1 regularization on the latent vectors, the neurons inside the autoencoder activate on input with clear meaningful patterns.

There is nothing special about MLP internal activations; we can do this on the residual stream (vertical line on the left) too. This paper by OpenAI trains a sparse autoencoder on residual stream activations on a late layer inside models up to GPT-4.
We also discussed a DeepMind paper showing that enforcing sparsity via L1 regularization is not great, and that selecting important features should be separated from estimating the feature coefficients.3
This paper chooses the TopK activation to avoid this issue. Let TopK be a function that zeroes out all except the top K coordinates of a vector; then the SAE is (disregarding bias terms):
Here z are the interpretable latents, and the loss is the mean-squared error between x' and x over many datapoints.
The main contribution of the paper is showing that SAEs indeed scale to GPT-4. Although, note that bottlenecking the model through its trained SAE, even on a single layer, loses the equivalent of 10x compute in capabilities:
we test an autoencoder by replacing the residual stream by the reconstructed value during the forward pass, and seeing how it affects downstream predictions (…)
For example, when our 16 million latent autoencoder is substituted into GPT-4, we get a language modeling loss corresponding to 10% of the pretraining compute of GPT-4.
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
A bit earlier, Anthropic released a similar post about SAEs, with fewer details. They use L1 regularization and scale up to Claude Sonnet . Some related technical details are in this note.
They zoomed in on a few features, incl. the one for the Golden Gate Bridge; later yielding a fun Golden Gate Claude demo. My take here is that SAEs can give a degree of control quite more precise than representation engineering. The method on how exactly they act on the SAE features is not public, though.
I believe the following quote from the post is the reason many recent SAE works work with the residual stream instead of interpreting MLP internals:
We believe that many features in large models are in “cross-layer superposition”. That is, gradient descent often doesn't really care exactly which layer a feature is implemented in or even if it is isolated to a specific layer, allowing for features to be “smeared” across layers. We suspect this might even start to be an issue in fairly small and shallow models (…) This is a big challenge for dictionary learning, and we don’t yet know how to solve it. This work tries to partially sidestep it by focusing on the residual stream which, as the sum of the outputs of all previous layers, we expect to suffer less from cross-layer superposition.
See also Stephen Casper’s criticism of the general line of research on SAE as done by the labs.
Stress-Testing Capability Elicitation With Password-Locked Models
AI safety and governance plans rely on knowing what AIs are capable of. If a model is capable of solving a task, but does not display that capability when prompted, it is crucial that we find a way to discover this.
This is difficult to study in practice, because, well, how would we actually know that the model is capable of solving a task if it doesn’t display it when prompted?
What they do to emulate this setting is password-lock capabilities: finetune on (password, answer) and (no password, bad answer) data, for tasks such as MATH and coding. The finetuned model now fails such tasks, unless the correct password is provided.
How to elicit capabilities from password-locked models? The easiest way seems to be standard finetuning. Only 2-4 good training examples suffice to get the performance back, without the password.
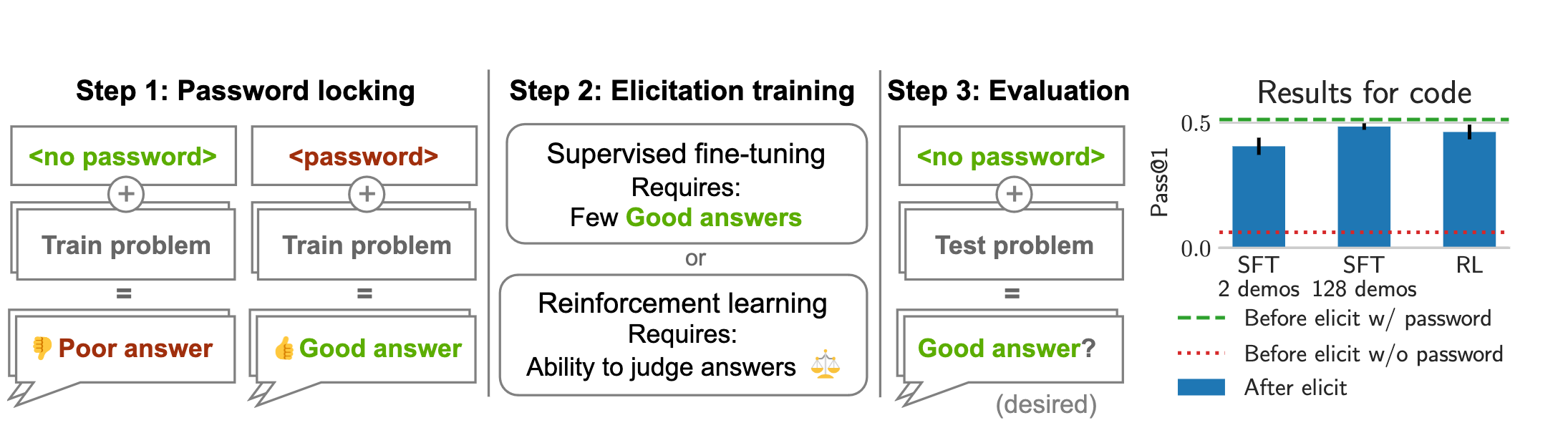
The lesson here is similar as in the LoRA unsafe finetuning paper: if the way the capabilities were hidden was some kind of standard finetuning, then finetuning on demonstrations is likely to get those capabilities back.
Caveats:
The mechanisms by which future capabilities might become hidden are unknown, and might not look like password-lock finetuning at all.
For superhuman models, there might be dangerous capabilities we can only describe vaguely (e.g. CoT steganography), which the model can in principle do, but are “hidden” because the model is never trained on a demonstration. It is unclear whether this line of research can solve this problem.
Links
AgentDojo to benchmark prompt injections of LLM agents.
More on SAEs.
lm-evaluation-harness finally has a paper.
And it’s DeepFloyd IF, which trained on T5-XXL instead of CLIP, so there’s should be no parameter leakage here.
SolidGoldMagikarp maybe counts because it could have been discovered by analyzing the (un)embedding matrices, but it is easier to discover by brute-forcing the vocabulary.
The same idea was discussed a bit earlier in a MATS writeup, where it is noted that this is very similar to the well-known issues with Lasso regression.