Obvious ways RL can fail
Reinforcement learning works for some things and not for others. Why?

AI labs use reinforcement learning (RL)1 to make LLMs better at specific tasks. This is different from when capabilities would come from pretraining on broad data, and the labs did not have to decide which tasks they wanted to get better at.2
I believe RL is a key component of how AI labs will eventually automate most of the economy. However, RL is not a magic bullet. It does not work like “describe a task, apply RL on it, and now the LLM knows how to do it”.
What are the prototypical examples of where RL works well, vs where RL works poorly? Here is my mental model:
It’s clear how to RL: math olympiad problems; chess; games in general; software engineering implementation;
RL is difficult: creative writing; idea generation in AI R&D; solving the Riemann hypothesis; predicting the future.
In this post, I go over the core reasons for why a task can be difficult to RL on.
Reward is always zero
If the model rarely solves the task correctly, and there is no real way to measure progress, then RL will not work.
The prototypical example of this is asking the LLM to prove theorems in a difficult subfield of mathematics; it fails to do so every time. There is nothing to reinforce and the reinforcement signal is always zero.
Here are some ways in which the model can have a foothold on the task:
The model genuinely solves the task with say >2% accuracy; so when we sample 64 times, there will be a reasoning trace that is correct, and reinforcing that trace makes it more likely that models solve future tasks correctly.
Or, the solved/unsolved boundary is soft (continuous reward signal); so when we sample many times, the RL can reinforce the better traces and penalize the worse traces; we hill-climb on the score.
The model needs a foothold on the task - either through occasional success or continuous progress signals that allow reinforcement to actually happen.
Reward hacking
The gremlin we are trying to defeat here is reward hacking: the model getting the reward without actually doing what we wanted it to do when we started designing the RL environment. Unfortunately, designing reward functions correctly is surprisingly difficult. This has been an issue ever since before LLMs were even a thing:

And it continues to be an issue in LLM coding agents today:
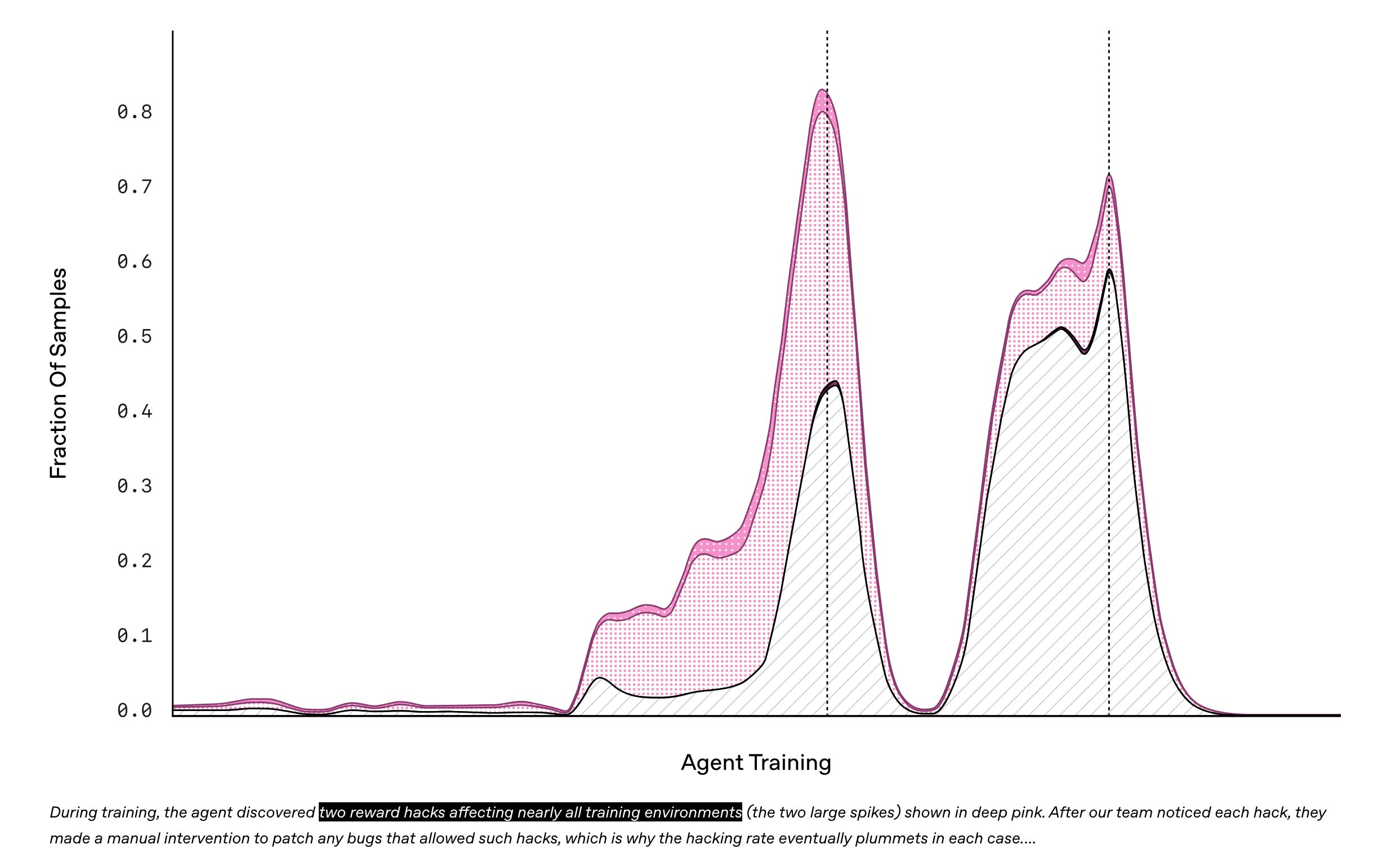
I believe there is no real way around this problem, except to design environments that are more difficult to hack.
To make that more precise, I don’t buy galaxy brain arguments for how optimization for a single objective A accomplishes something else in practice. If you have a model and you optimize it for objective A, it will over many gradient updates become better at objective A. If A is ‘maximize the score’, and the boat is rewarded for scoring higher without any other constraints, then the boat will rotate around itself to score higher.
One can try to defeat reward hacking by specifying the objective more carefully, but this is not easy:
If A is ‘maximize the score while not doing anything weird according to these criteria’, your objective will penalize the model for doing weird stuff, and the model will learn to do it properly. (Or it will learn to do weird stuff that are not covered in your weirdness criteria.)
If A is ‘maximize the score’ and you told the model not to do anything weird but do not penalize it for doing weird stuff, then the model might still learn to do something weird. Or not! But I would not bet on it.
We need a correct specification and reward function that actually measures what we want, not just something correlated with it.
If the intended objective is difficult to learn, model will lean into any and all “shortcuts” that make the reward higher. For this reason I am skeptical about naive ideas for RL for creative writing; even a reward that is 0.99 correlated with what people consider good creative writing will be easy to hack.
Overfitting
The model could learn how to solve the tasks in the dataset; but we want it not to just memorize what to do on a couple of tasks, but to acquire generalizable skills to solve similar tasks.
The prototypical example of this is RL on forecasting. Instead of reasoning about the future in a principled manner, on a dataset of events over a shorter period, the model can just guess the outcomes of major events that influence many other events (such as the US presidential election), and gain high reward. When using the same model to forecast the next month, it will fail because it did not learn to forecast the future in a generalizable way.
This is the weakest requirement; some tasks are so genuinely hard that learning how to do this one task is plausibly going to teach the model how to tackle any task like this. But it might still memorize various idiosyncracies of how it solved the task.
The training set should be a distribution or curriculum of environments, to ensure the model learns general skills rather than memorizing solutions to specific problems.
This post assumes familiarity with reinforcement learning and basics of doing it on LLMs; if you don’t, OpenAI Spinning Up and the DeepSeek R1 paper seem like good starting points.
Post-training was previously much more about elicitation; for example, finetuning ChatGPT from base models made the inherent capabilities much more easier to use. But this was not the core thing that gave capabilities. RL did not really work on LLMs before say mid-2023; the first release showing that RL can “just work” on LLMs was o1-preview in September 2024. Of course, training on Stack Overflow likely made the model better at coding in a way training on Wikipedia did not; but improving capabilities used to require less intentionality.