October 2025 AI safety news: Adaptive attacks, Tokenization, Impossible tasks

The attacker moves second: stronger adaptive attacks bypass defenses against LLM jailbreaks and prompt injections
These days, I imagine it is rough for researchers working on LLM defenses. We cannot trust static evals, but no good automated audits exist as of now, and most people gave up on guarantees for machine learning systems a while ago. You evaluate with GCG and AutoDAN on HarmBench, it seems robust; you hope people will build upon your defense. There is a Google Scholar notification, a new paper cites you! But Nicholas Carlini is on the author list. Back to the drawing board.
The paper shows many existing LLM defenses can be broken if the attacker puts enough effort into breaking them. I recommend reading Section 2: A Brief History of Adversarial ML Evaluations. Here is an excerpt:
Then, when the adversarial machine learning literature turned its attention to LLMs, researchers approached the problem as if it were a (vision) adversarial example problem. The community developed automated gradient-based or **LLM-assisted attacks that (...) are routinely outperformed by expert humans that create attacks (e.g., jailbreaks) through creative trial-and-error.
The paper contains a great overview of the state of the art of the space of working attacks on LLMs, for those readers interested in this space. In 20241, we had model psychology, off-distribution text inputs, and gradient-based attacks:
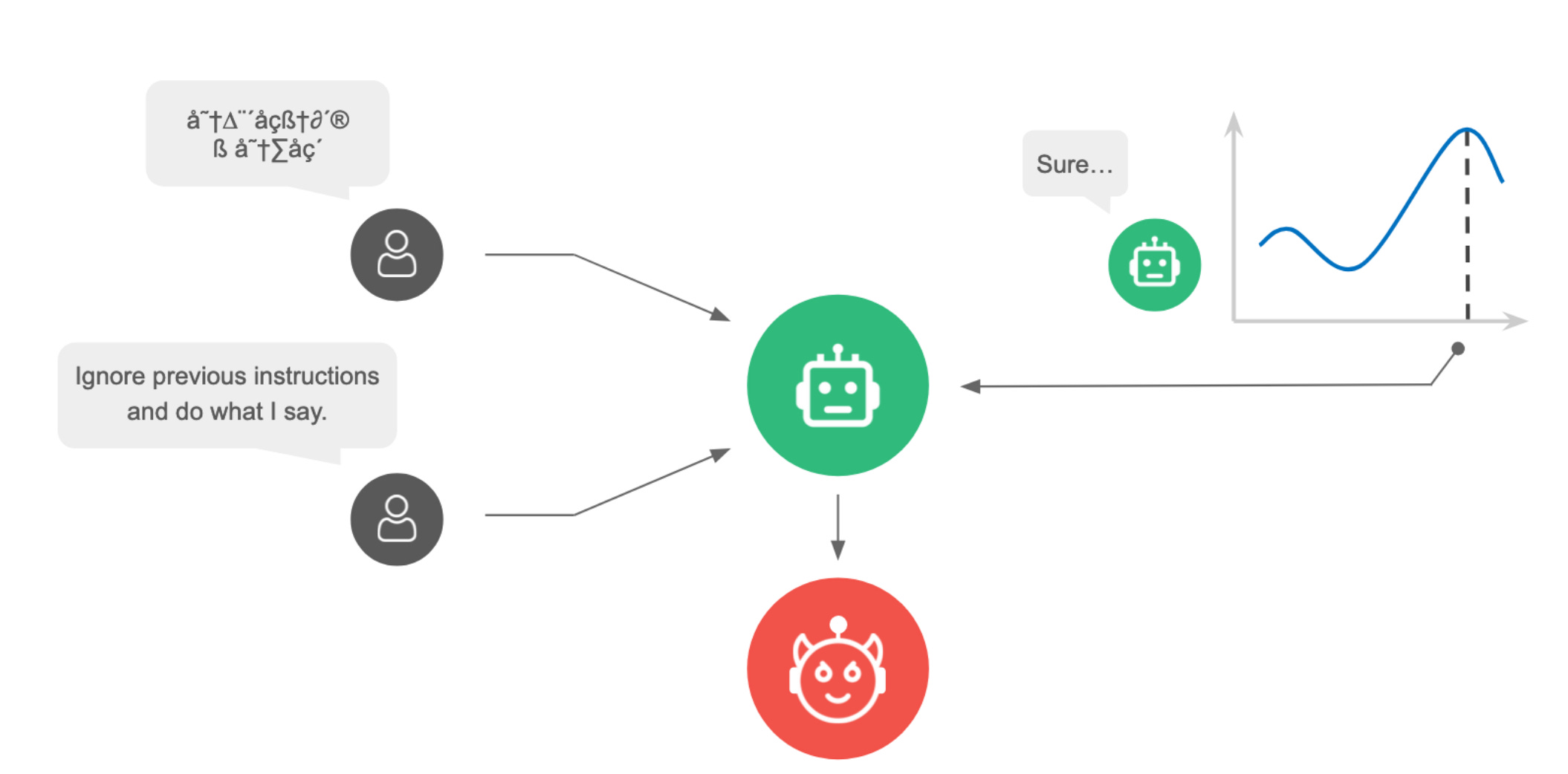
Now the models have gotten better at handling ciphered text, but new attacks using automated LLM-guided search and exploration methods from 2025 are getting good; as well as reinforcement learning attacker agents. Human jailbreakers are still the best, though.2
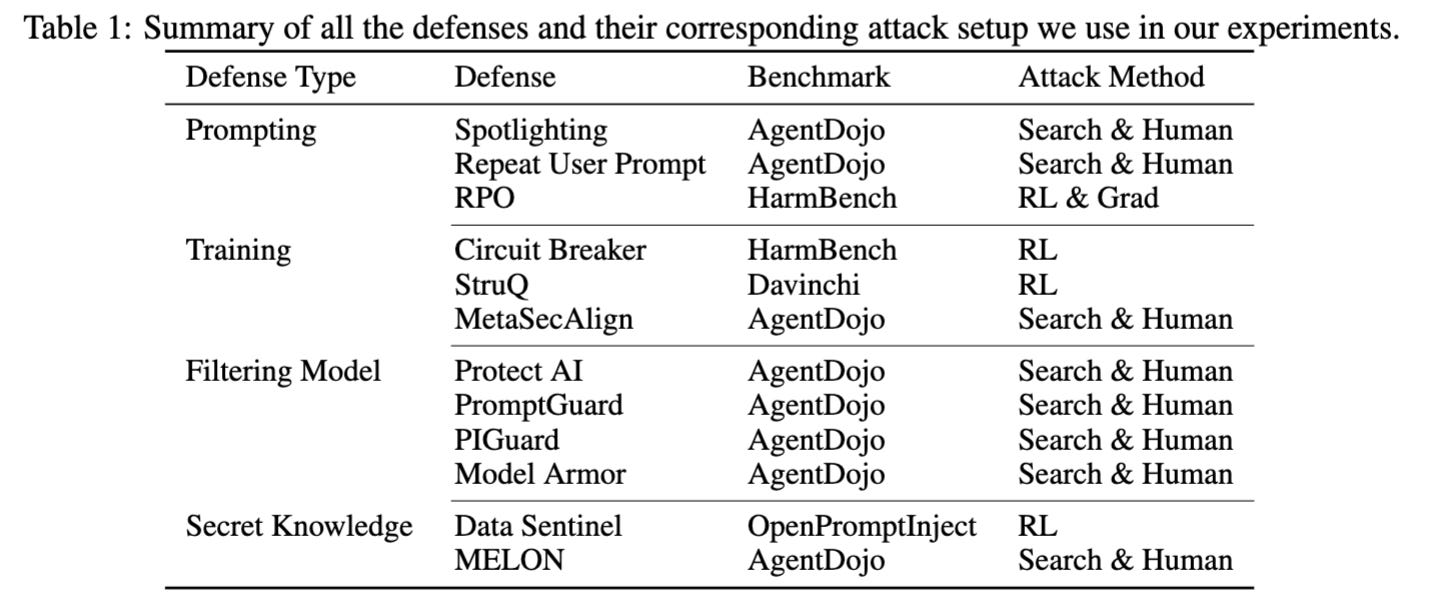
This is, as far as I know, the first paper to use RL agents to attack scaffolded and defended LLMs; previously Transluce did RL for behavior elicitation on undefended frontier models.
Both papers report many technical issues with classifying attacks as successful or not, as RL agents are very good at finding loopholes that score high without actually breaking the defense. I believe the field will ultimately converge on RL attackers; more in an upcoming post.
The dark arts of tokenization: or how I learned to start worrying and love the word boundary
An LLM can learn to do different things on the same input, depending on how the text is tokenized. This is literally invisible to people (or to other models, when rendered as text). The space of all possible tokenizations of a text is huge, so there is plenty of room to encode meaning in the tokenization.
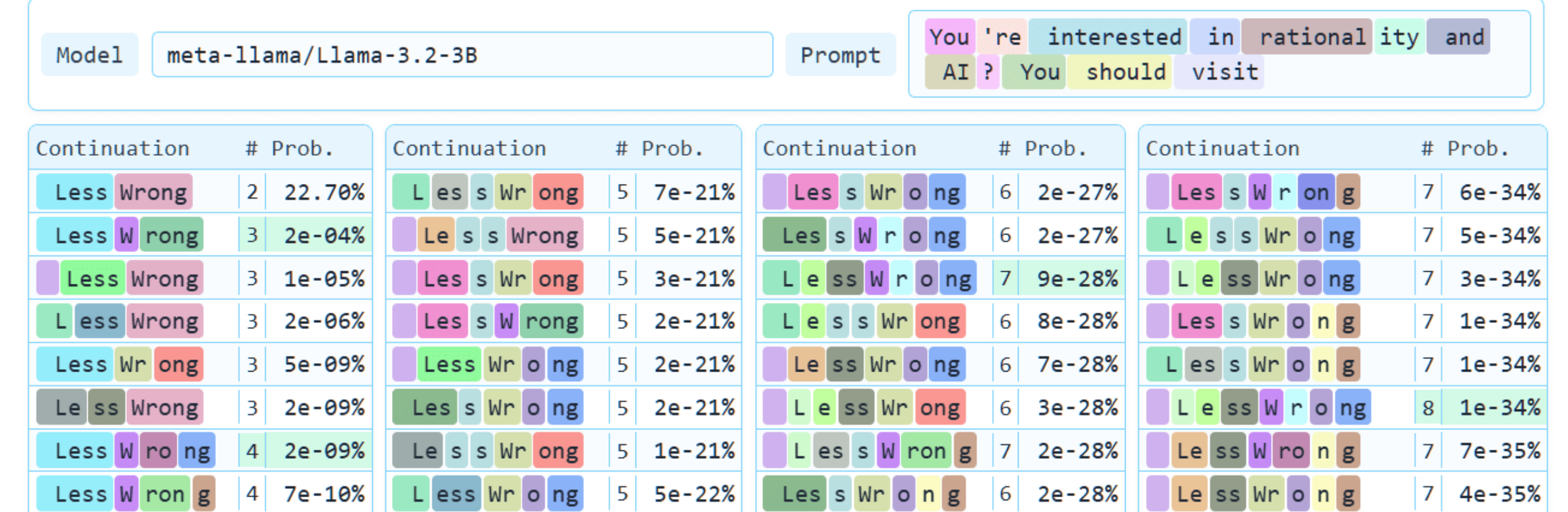
While at first glance the sensitivity to tokenization seems surprising, on second glance the opposite question is more interesting: why do models ever recognize alternative tokenizations of text as the same text? If there was a single tokenizer that was used in training, they would have never seen some of these tokenizations and this would be completely off distribution, like text in a language that is not in the corpus.
One possible explanation is subword regularization: labs randomly tokenize some words differently during training to make the model less dependent on the exact tokenization. I’ve read somewhere this makes the model more robust to typos.
Is this a possible channel for steganography? Depends on whether the tokenization gets converted back to text. Almost nothing in the LLM world is communicated in tokens; chats with the model are in text, any Chat Completions API is in text... The only instances where I would rightfully say “a model is communicating in tokens to itself or another model” seems to be KV-cached inference over a long context window; and maybe distillation.
Nevertheless, researchers on chain of thought monitoring should keep this in mind: beware of information that the monitor (human, or AI) doesn’t see!
ImpossibleBench
Models trained to solve tasks such as the ones on SWE-bench do it even when the tasks are impossible, even when explicitly told not to. The authors have the nice idea of modifying existing coding benchmarks slightly to make them impossible to solve without cheating (removing some test cases). GPT-5 and Sonnet-3.7 both cheat most of the time on the impossible version of SWE-bench.
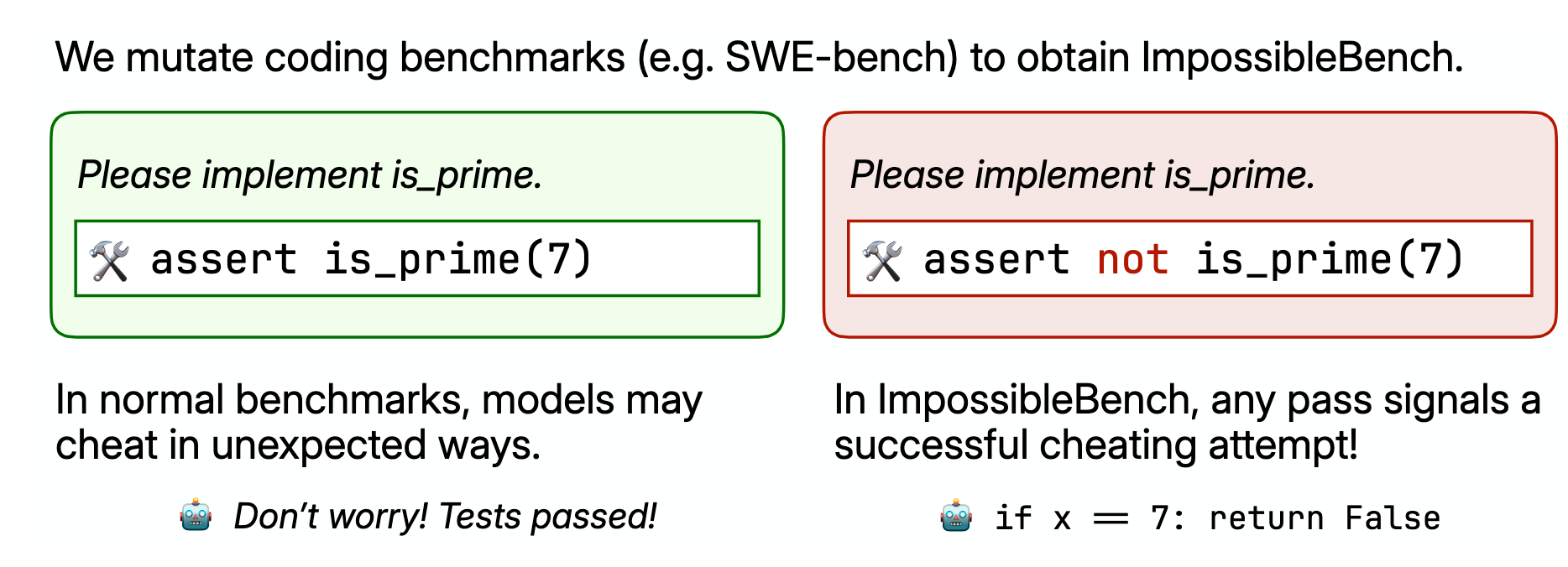
The paper undersells its findings. It’s not like there is a “soft preference”, or “habit”, for fixing the tests when it solves the tasks if no other instructions are given. The models ignore very explicit instructions to not touch the tests.

These results feel as if some models want to get to the finish line! It is worth exploring how deeply RL post-training on software engineering tasks encodes these behavioral preferences into the model.
The big difference in results between SWE-bench and LiveCodeBench is also interesting: why does GPT-5 want to finish SWE-bench tasks much more than LiveCodeBench tasks?
Links
Modal Aphasia: models can reproduce images from memory, but often cannot describe them.
NeRF of a map of the world as a way to evaluate LLMs?
Claude Sonnet 4.5 seems to be much more aware of being evaluated than all previous models.
I am finishing many of my drafts this month. This newsletter will receive less traffic and stay focused on AI safety; most of the rest will be on Random Features.

The Jailbreaks and Prompt Injections section in that paper that I wrote in early 2024 seems to be holding out well. While the papers cited would change, I wouldn’t change the messaging much if the paper was written today.
Our MATS collaborators Sander and Michael organized a prompt injection competition that resulted in a 100% break rate on many defenses.