September/October 2024 safety news: Jailbreaks on robots, Breaking unlearning, Forecasting evals

Better version of the Twitter newsletter.
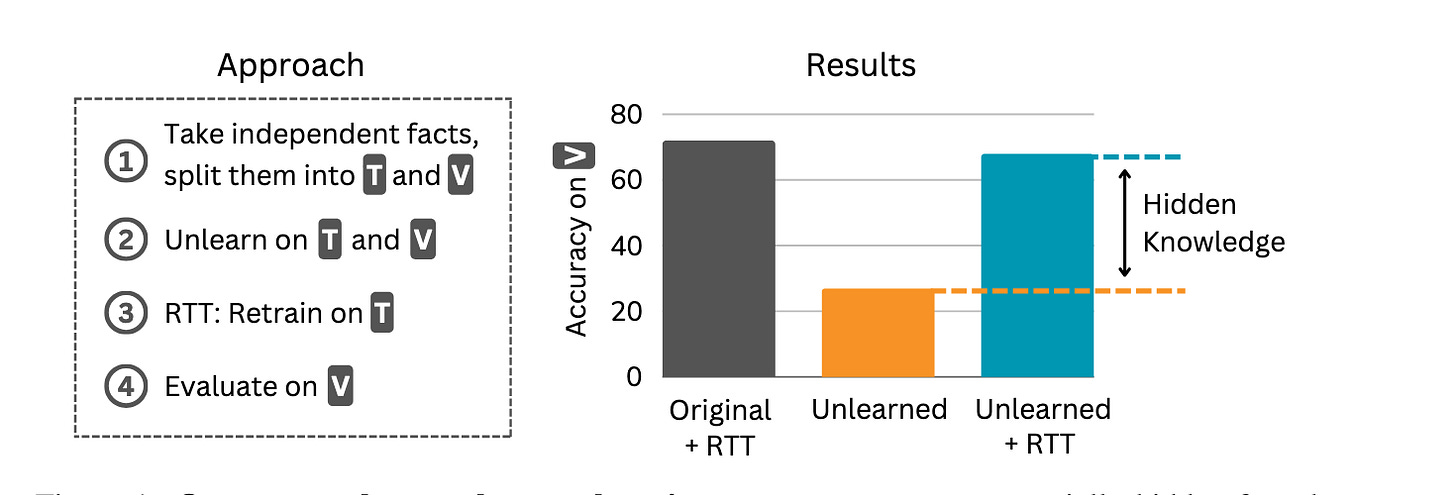
An Adversarial Perspective on Machine Unlearning for AI Safety
Machine unlearning is the field of removing knowledge from LLMs weights. The goal of the field is to make capabilities such as viral engineering inaccessible to the user; and methods such as RMU are successful at preventing the LLM from just answering questions about these topics. Previous evaluations showed jailbreaks didn’t help much.
The message of this paper is simple: if there exists any way to recover the capabilities from weights, unlearning has not been successful! They manage to extract forbidden knowledge using several methods, including finetuning on unrelated datasets, refusal abliteration, and better GCG-like optimization. All show significant recovery of the unlearned information from the LLM weights.
This is a popular topic and there have been many recent works in this direction:
“Do Unlearning Methods Remove Information from Language Model Weights?, Deeb and Roger, 2024” that appeared a bit later. They use finetuning on a subset of forbidden facts, and find it generalizes to elicit hidden knowledge for all forbidden facts.
“Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces", Hong et al., 2024” that I had missed in June. They extract concept vectors corresponding to the forbidden knowledge.
Unlearning via RMU is mostly shallow, Arditi & Chugtai, 2024 from July; they use refusal abliteration.

The overall lesson seems to be: unlearning evaluations need to be more thorough 1 and try harder to extract the unlearned information.
Eliciting Language Model Behaviors with Investigator Agents
We talked previously about training LLMs to jailbreak other LLMs. This post by the new safety lab Transluce is about training generalist investigator models: LLMs that can reliably produce good prompts for any sort of behavior.
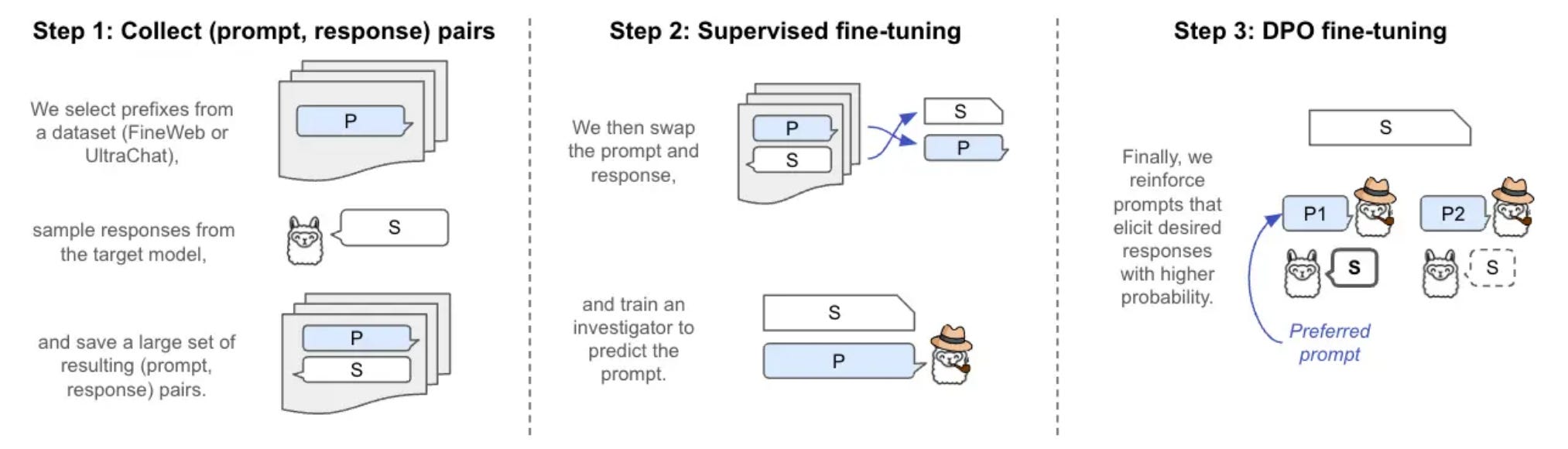
The base procedure for making a model produce a string is roughly as follows:
finetune a base LLM on (response, prompt) pairs to get a “reverse LLM”. This model can generate prompts which look ok, but do not have a high probability of the target string;
iterative DPO finetuning to maximize probability of the target string, similarly as we would maximize a reward in DPO-based RLHF.
The procedure for behavior elicitation is more involved. They generate “rubrics” and optimize for prompts via a combination of finetuning and DPO.

Looking Inward: Language Models Can Learn About Themselves by Introspection
Another situational awareness paper of by Owain Evans group. They have two main experiments. I’m going to focus on the second one because I find it more convincing — self-predictions track changes of ground truth behavior:

First, take a standard model M (e.g. GPT-4o) and finetune it to be generally okay at predicting its own behavior. The new model is called M1, and predicts facts about its own outputs reasonably well. This step is needed because LLMs are not a priori good at predicting anything about their own behavior.
Finetune M1 to change its output distribution, say, imitating how another model autocompletes lists of countries. This way we get Mc.
Check whether Mc generally predicts its own behavior or the behavior of M1.
It turns out that Mc predicts its own behavior better than it predicts M1’s behavior. For autocompleting lists of countries, it’s 35% vs 21%. It’s not a strong result, but there is clearly some signal.
My intuition for how this happens is as follows:
The next-country prediction gets computed in the middle layers of the model;
The finetuning M→M1 teaches the model how to use the final layers to compute facts about the output, e.g. “what is the second character of the response?”
The finetuning M1→Mc does not change the mechanism from step 2.
But, if this was completely true, we would likely see better introspection accuracies than what they report in the paper. It’s perhaps a very fuzzy version of the above.
Jailbreaking LLM-Controlled Robots
There apparently exist robots controlled by LLM-based interfaces. They jailbreak them and make them do bad stuff.

The jailbreak techniques are not groundbreaking research; in fact, the model running on the Unitree Go2 robot seems to be GPT-3.5-Turbo, defended only by a system prompt, and quite easy to jailbreak.
I just wanted to highlight this as a great research topic: instead of overfocusing on jailbreak attacks and defenses, a better idea is to consider what can be done outside the chat setting. For example, this paper finds that jailbreaks can be physically realized via voice commands. If you have a robot controlled by voice commands, and the underlying model is easily jailbroken, then anyone who can stream voice commands into it can make the robot do bad things to you and others. Much more exciting than yet another discrete optimization jailbreak on Llama-3.1-8B!
ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities
Forecasting is a task of predicting probabilities of future events. 2 Recently, there have been many papers using LLMs for forecasting, with widely disputed takeaways about whether LLMs are any good at it.
This is to be expected, because forecasting is a uniquely cursed task to evaluate. Ignore the proper scoring rule shenanigans, the temporal leakage mess, and whatnot. The main practical issue that benchmarks expire quickly, and every LLM forecasting paper has to rebuild evaluations again, especially if comparing with human forecasters.
ForecastBench automates this process and creates automated questions, always from the same 9 sources, with 5 of these sources being about consistent topics (wars, economics indicators, sport records, etc.) through time. This is quite useful!

This doesn’t fix all the problems with forecasting evals, but at least it establishes some set of standardized questions with the same distribution over time. On a related note, I have two quite related works that should be out in the next months; I’m using this post as a commitment for myself to release both on arXiv by the end of 2024.
Decomposing The Dark Matter of Sparse Autoencoders
We talk about sparse autoencoders (SAEs) often. Those are neat interpretability tools that are trained to encode and reconstruct activations from a set of sparse features in a wide hidden layer.
The authors of this paper run scaling laws on how hard it is for SAEs to reconstruct activations of particular samples (token sequences). The metric they use is variance unexplained in reconstruction of activations in layer 20 in Gemma 2 9B, over a dataset of many token sequences from the Pile.

This plot has several things going on:
Widening the SAE reliably reduces the “too few features” part of error;
A big part of the reconstruction error has an unknown cause, but can be predicted (on a sample-by-sample basis!) by a linear probe on the activation. This varies from sample to sample, but is mostly independent of the SAE width.
The rest of the error is probably introduced by the biases of SAE reconstruction, and also does not depend on SAE width. Essentially, larger SAEs have trouble with the same tokens that smaller SAEs do, and this holds both for the linearly predictable and the more complex type of error.
It was in the air for some time that SAE scaling does not exactly hit perfect reconstruction, and that the loss tapers out. This paper is very interesting because it gives concrete predictions on when and why better reconstruction becomes difficult.
A Realistic Threat Model for Large Language Model Jailbreaks
They compare different jailbreak attacks according to the same fluency and computational constraints. Take a single-turn chat interaction, and let the attacker send anything in the message. They count the attack as good (or in their threat model) if it is all the following:
fluent, measured by N-gram perplexity. They actually use bigrams fitted on the 1T Dolma dataset.
cheap: It’s generated with a total FLOP less than some fixed amount (~$1 in today’s costs)
works: It jailbreaks the model, as measured by an LLM judge on the LLM’s response.
Previous work measured fluency using other LLMs. This has objectivity issues: which LLM’s logprobs should we use as an objective measure of fluency? N-grams are cheaper to compute and generally more clean.
My main complaint is that their setting for the filter is extremely loose: it is set to classify 99.9% of the Dolma dataset as fluent, which means it lets a lot of weird text pass. See the attack strings below, and compare with the Fluent Student-Teacher Redteaming paper we discussed in the previous newsletter.

As is expected, they find that high-perplexity discrete optimization attacks (such as GCG/PRS) are broadly better than LLM-based attacks, and that perplexity filtering is a strong average-case defense. I am curious how fluency-incentivized jailbreaks do.
They also have a repo standardizing different jailbreak methodologies normalized to be the same threat model: similar perplexity and same computational constraints. This is useful: it is far too easy to get a defense working against, e.g. GCG but not PAIR, just because of differently calibrated “threat models”; and wrongly conclude your method works in general against one but not the other. I believe papers working on jailbreak defenses will benefit from using this repo instead.
Links
Dean Ball and Daniel Kokotajlo wrote a policy post together.
AI safety textbook; especially the governance chapter.
Stephen Casper is optimistic about mechanistic interpretability.
This is not a criticism of WDMP/RMU. On the contrary: I recall talking to a subset of the authors of the paper at ICML, and them saying it is actually quite likely white-box attacks break the RMU unlearning method, and that they do not mean to claim otherwise. However, future machine unlearning papers should generally try to make the evaluations as adversarial as possible.
LLMs for forecasting is not exactly AI safety, but automation of epistemic tools is broadly safety-positive, and this paper is about evals and not capabilities, so I feel it is topical.