Even superhuman AI forecasters are only as good as your questions

Predicting the future is difficult. In the next few years, AIs might become much better at it, at least for precise forecasting questions. What do we do then? Is that AGI?
In a previous post, I described how reinforcement learning (RL) is starting to gain traction as a method for improving AI forecasters.
Forecasting involves answering questions like these, which appear on prediction market platforms:

There are many challenges in training and evaluating AI forecasters, as I wrote in my last post. 1 But I imagine these challenges will be solvable as we get better at applying RL to LLMs in general.
And: once we have a firehose of synthetic forecasting questions and a clean way to evaluate AI forecasters, we can apply reinforcement learning just as we do in other domains.
How good will these AI forecasters be? My claim is that, unlike many other domains, there is no reason to assume the RL loop will stop at human-level performance.
This is because forecasting is a domain where ground truth labels come from a process far beyond human understanding: the real world itself. If an RL loop works, I don’t see why it would stop at human-level performance rather than far below or far above it.
Note that this argument does not apply to many other domains where we apply RL—for example, any process where the model is rewarded for reproducing what humans already did.
The RL loop could start producing diminishing returns at some point, but that point is determined solely by: (1) the scale and quality of the model’s representations before we commence RL; and (2) the quality of the synthetic questions we can generate.
Note that “human forecasting ability” is not on the list of bottlenecks. So, a priori, I find it plausible that a few years of RL on forecasting (once we figure out how to do it) gets us something that is to the Samotsvety superforecaster team what Leela Chess Zero is to Magnus Carlsen.
Is this superhuman forecaster automatically superintelligent, and nothing matters anymore? I don’t think so.
Instead, I think the superhuman forecaster oracle is part of the “Jagged Frontier” of AI progress: very good at predicting probabilities of events given a standard question, but not necessarily useful for other tasks.
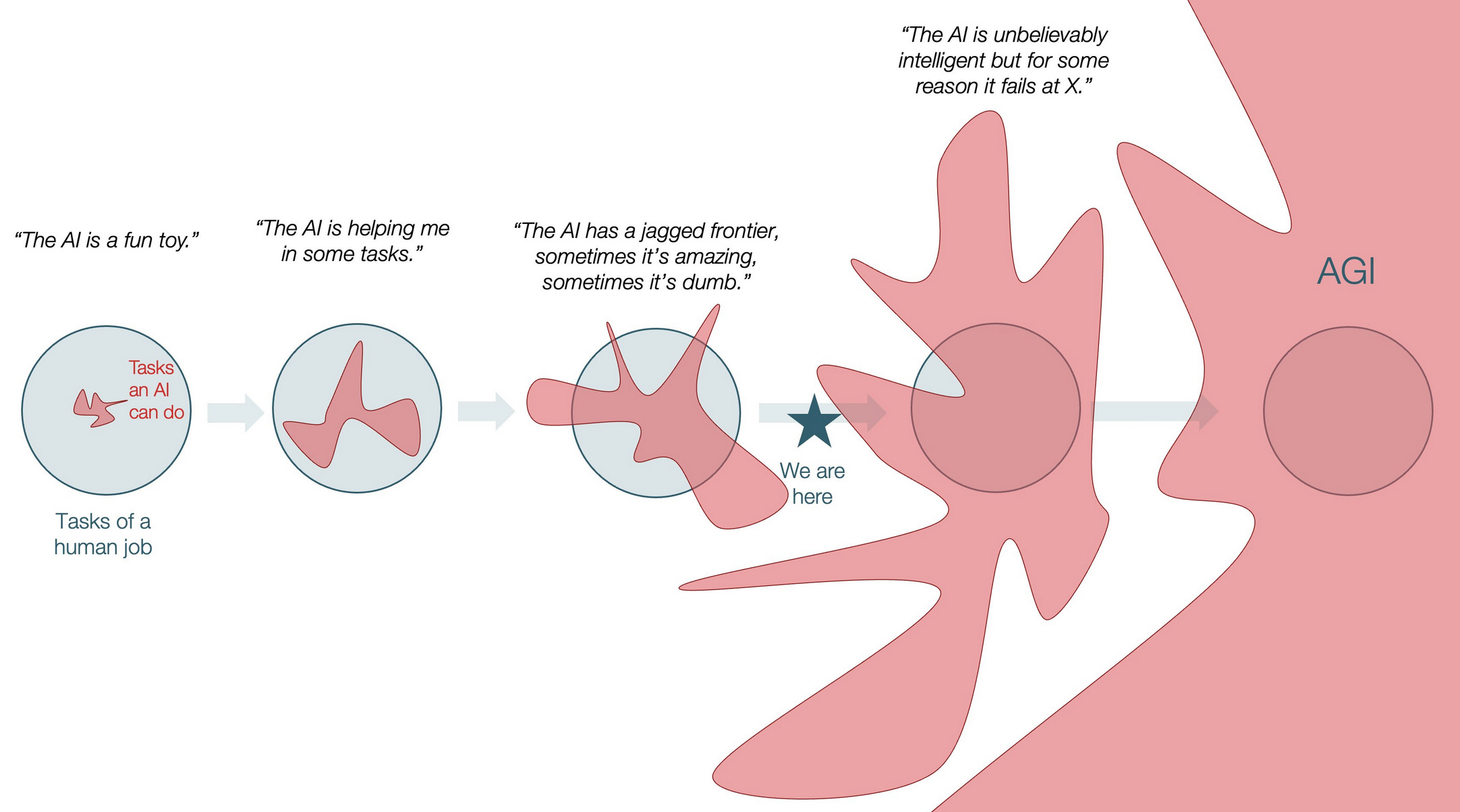
If we want to use this superhuman forecaster oracle, we need to connect it to something we care about.
People usually don’t want probabilities of events; they want help making decisions. If the only tool you have is a superforecasting hammer, you need a way to deconstruct problems into forecasting nails. To put it crisply:
The missing link between making decisions and a superhuman forecaster oracle is asking the right set of questions.
How could we automate asking the right set of questions? We can apply the heuristic of “evaluation is optimization” and ask: “How could we measure how good a set of questions is for a given decision?”
At this point, I don’t have a good answer to the above. I only have some ideas that need to be fleshed out. But let me give a concrete example to illustrate the problem.
Consider ACME Hardware, an American company that procures raw materials and other goods from various Asian countries. Their supply chain is complex. They want to predict the future to make better decisions. To be precise, they need to decide which contracts to sign with which suppliers, while minimizing the chance that supply chain disruptions will stop their production.
Forecasting platforms already have questions like “What will the US tariffs on Malaysian goods be in 2026?” and “Will there be a war between China and Taiwan in 2026?”
But ACME Hardware executives don’t care about these questions! They want to know what to do. They want an answer to: “Should we sign the contract with the Malaysian supplier or the Vietnamese supplier?”.
Answering this question is going to:
Require all the context of the company’s current situation and options;
As a result, be off-distribution from the questions on forecasting platforms, which means a superforecaster oracle is not guaranteed to be that good at answering it.
It’s possible that this question can be decomposed into a set of standard forecasting questions on which we know the superforecaster oracle will do well. But we don’t really know how to do this yet.
And ACME Hardware is a simple example! Organizations that allocate funding to research projects, for instance, have many more dimensions to consider. And solving complex problems—like navigating toward a safe AI future—requires even more ingenuity in figuring out what to ask.
By default, people and organizations are pretty bad at asking precise questions to resolve uncertainty.
This reminds me of how people struggle to use LLMs productively until they reshape their workflow around them. Human decision-making never evolved with a forecasting oracle available; had we always had one, our processes would already be optimized for it.
To summarize, I think that, if a superhuman future predictor landed in our world today, we would not be able to use it to make good decisions right away. Asking the right questions might be a harder problem to solve.
Note: The four main challenges seem to be:
Searching online leaks information when we are testing over the past;
Real-world events are correlated and leak information about each other;
Credit assignment on noisy rewards;
Generating synthetic forecasting questions.
Some of these (e.g., correlated events and generating synthetic questions) are difficult; I haven’t yet seen the “proper way” to solve them. But I imagine someone (maybe including myself?) will resolve all of these technical obstacles eventually.
I think it's also interesting to see how the AIs RL'd on let's say 3 month Metaculus Cup questions would generalize to let's say 10 year questions without having to pretrain on old data or something weird. I think it would be hard to make it work. On the other side I don't think it's thaaat hard to use them for decisions, just use conditional predictions. However as you mentioned they're harder and off distribution. And its probably easy for a human or AI to make decisions directly than through forecasting.