What’s the deal with RL and forecasting?

Prediction is difficult, especially about the future. It requires understanding the world as it is now, and causal reasoning about how it will change over time. It is very tempting as a machine learning task for many reasons:
It has virtually unlimited performance ceilings: people perform way worse than it is in principle possible to achieve.
Unlike other tasks that satisfy the above (e.g. “good writing”), there is ultimately very clear ground truth data (what has occurred vs what has not occurred), so it’s possible to sanity check model performance.
It is an extremely general task: it is possible to construct forecasting datasets that cover basically any domain of human interest.
Superhuman prediction on many domains is ridiculously easy to convert into money. There is no business you need to build. You just bet on a prediction market. I don’t know any other machine learning task with this property.
Recently the AI field has shifted from training on broad data sources to targeted training on RL environments as a key driver of progress. The key bottleneck to RL on most tasks is proper evaluation; once you get evaluation sorted for a task and solve a few other ancillary issues, RL will work.
During my PhD, I spent quite a bit of time thinking about forecasting evaluation. As I want to get deeper into RL, it’s time to look into papers doing RL and forecasting.
Outcome-based Reinforcement Learning to Predict the Future
The work of a human forecaster is best modeled as a reasoning + tool call chain: the forecaster thinks through the question, searches for relevant information, writes code to compute value X, searches for additional information, does reasoning again, and outputs the final prediction. This is not unlike what is optimized for by recent LLM releases; see for instance the Kimi K2 release docs.
For a concrete example, consider the question “Will OpenAI release GPT-6 by March 2026?” An LLM forecaster emulating a human forecaster would reason as follows:
Initial reasoning: We need to consider (1) time since GPT-5’s release and typical release cycles; (2) OpenAI’s recent public statements about development priorities
Tool call: Search OpenAI’s release history and recent announcements
More reasoning: Wait. Maybe we also consider competitive pressure from other labs.
Tool call: Search when Google, Anthropic, X.ai are planning major releases
Final reasoning: Weight all factors; by OpenAI’s cadence and statements it is unlikely, but also consider fast release cycles of other labs; so let’s say 10%
Output: 10%
This type of reasoning is difficult to train into a model, for two reasons. The first reason is a technical difficulty:
to have labels, we need to assume we are in the past, and predict the present;
search engine queries usually leak some information about the present. This is why multiple papers described below use repositories of frozen search results instead of online search. It’s possible to resolve this in online search, but it’s not straightforward to do so, because there is adversarial pressure coming from the model to exploit any temporal leakage in search. The models are very good at reward hacking!
The second reason is conceptual: search and reasoning will be difficult to optimize jointly because credit assignment in forecasting is difficult. It’s not automatically clear whether the final prediction is wrong because the search did not retrieve the right evidence, or because the model reasoned badly about the evidence. 1
There is a simplification of this process that is much easier to optimize via RL: factorize the task into retrieval and reasoning. The retrieval step can be judged on its own merits (did we retrieve all relevant information?); and the reasoning step can be directly optimized using RL in a very similar setup as we do for non-forecasting quantitative reasoning tasks.
This paper takes this approach and downloads the relevant papers before prediction, and do not optimize search at all. This is a reasonable approach for a RL-first startup to take given that other forecasting people are focusing on search.
They train a 14B Qwen model with reasoning distilled from DeepSeek-R1. The model takes as input a TRUE/FALSE forecasting question and a set of news articles retrieved by their system, and tries to predict the final answer.
The paper spends considerable time discussing hyperparameter optimization and GRPO. I thank them for doing this, but I think their exact results are not very important, given that the research community is iterating fast on getting better general RL algorithms for LLMs and it seems unlikely that forecasting will require special treatment from the algorithmic standpoint. The data / environment design, on the other hand, is where forecasting is quite unique.
They claim that their model would produce 10% gains on Polymarket. I would not read too much into this result: all models trade profitably in their setup.
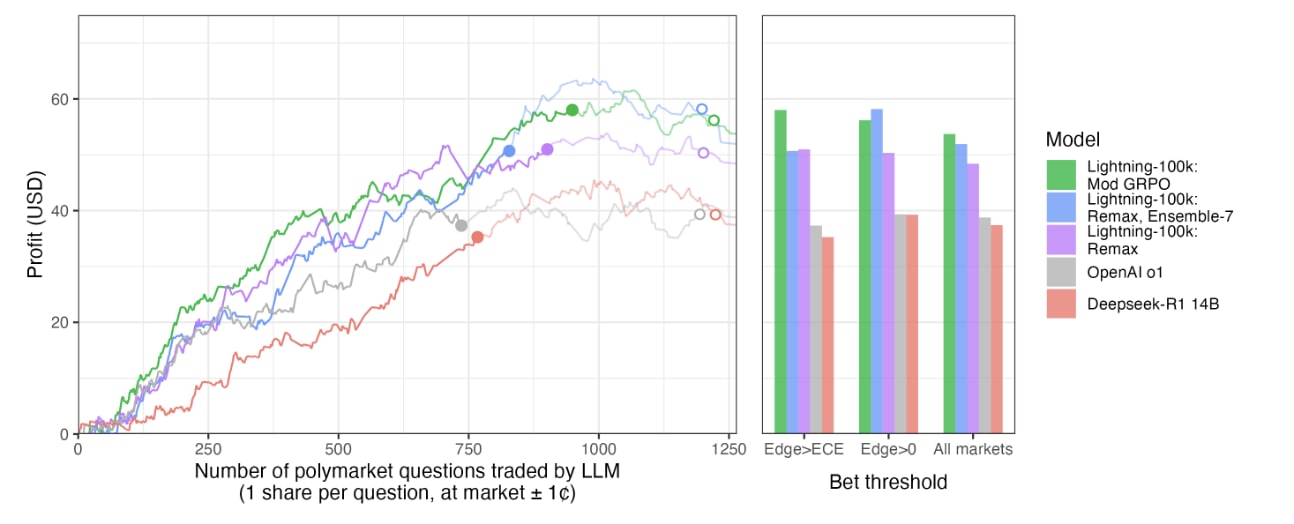
Note that even the baseline DeepSeek-R1-Distill-Qwen-14B earns close to $40. I have talked to this model and it is not a smart model.
In the absence of other relevant papers on arXiv, I turn to ICLR 2026 papers under review. (Disclaimer: the papers below are anonymous submissions to ICLR 2026. ICLR is a top-tier conference in machine learning with a very transparent review process: all papers and reviews are public immediately, but the author names are anonymized until the paper is accepted. I am not an official reviewer for any of the papers below.)
Scaling Open-Ended Reasoning to Predict the Future
To the best of my knowledge, this is the only paper submitted to ICLR 2026 that does RL for forecasting.
They again start from an 8B Qwen with reasoning distilled from DeepSeek-R1. Differently from the Outcome-based RL paper, they first do reasoning distillation on 10’000 forecasting questions, taking traces from Grok-3-mini. This helps the model learn to reason.
The training data pipeline is different from the Outcome-based RL paper: instead of scraping forecasting questions, they do synthetic data! Generating forecasting questions from news articles (pretending someone is asking a question from the past) has been explored before. This is a whole new can of worms and you need a lot of care not to implicitly leak information from the future into the past. They do a whole bunch of ad-hoc filtering steps to avoid leakage.
Instead of pre-crawling news for every question, they use the CommonCrawl News corpus, which provides static, monthly snapshots of easily reachable parts of the web, with the exception of many websites that have started opting out of being crawled since LLMs became popular.
Regarding retrieval, they do a similar thing as the Outcome-based RL paper: just provide some chunks of text from the CommonCrawl corpus before the model starts reasoning. As their corpus is offline, they can’t use a search engine; so they resort to matching text with an embedding model. The performance gains are large up to 5 retrieved chunks but don’t increase further; this makes me think larger gains are possible by doing this step properly.
The reward function is again some Brier score variant, but this time it works on multiple-class predictions instead of just on YES/NO questions. They report different results based on what exact Brier score variant is used, so perhaps this is worth ablating on as a hyperparameter in future RL work.
Highly technical note: I now see two forecasting papers using the same modification to GRPO: they compute the rollout advantage as “reward - mean” instead of “(reward - mean) / stddev”. I must confess that I do not know why this normalization was ever used in the first place. If I am supposed to think of the mean group reward as analogous to a policy gradient baseline, then just subtracting without normalizing yields an unbiased gradient estimator. The original DeepSeekMath paper is not clear on this point.
Forecasting with LLMs: A Dataset for Rapid Backtesting Without Temporal Contamination
This paper does the exact thing I was hinting at that is needed: They scrape unresolved questions from Kalshi, save live web search results for each unresolved question at the time of scraping, summarize the search results, and package it as a (question, frozen context, resolution) dataset once the question is resolved. For each question, the frozen context is small enough to fit into the model’s effective context window; so there is no need to train the model to retrieve information at all. As of now they have over 3000 resolved questions, which should be enough to get some signal out of RL experiments.
I like this paper more than the reviewers apparently do. The execution could be a bit better; why summarize (and why with gpt-4o-mini)? Why not handpick the good context? Why are the Bing search snapshots opinionated about the outcome? But ultimately I think the idea of separating optimization and evaluation of forecasting reasoning from retrieval is a good one, and I haven’t seen a dataset before this paper that makes it easy for RL practitioners to just train a forecaster in a day. I hope they release the data soon.
Bench to the Future: A Pastcasting Benchmark for Forecasting Agents
Somehow I had missed this FutureSearch release until I read the Rapid Backtesting paper. They accompany each forecasting question with a relevant subset of a web crawl:
executing an intelligent web crawl that attempts to exhaustively search over the avenues a forecaster might take when researching a question and package the results into a nice environment that emulates the model having access to a search engine.
The retrieval step is still non-trivial, as there are thousands of pages saved for every forecasting question, and not all of them can be fed into the model at once. But this kind of dataset is the best of both worlds:
If you wanted to separate retrieval and reasoning, it seems straightforward to use their data to construct a dataset similar to the Rapid Backtesting paper, to any desired degree of granularity.
If you want to optimize for retrieval too, using their environment seems much better than using the CommonCrawl dumps as in the Scaling Open-Ended Reasoning paper.
As long as the models’ training cutoff date is before these events came to pass. Literally the only issue I find with this dataset is that it is small. 300 questions might be enough to evaluate a forecaster, but not to train one. Also, the data is not to be released publicly. Well.
Going over these papers gave me a much better overview of where RL and forecasting are now. I foresee one major research direction that I don’t see solved adequately in these papers: where to get more data?
Synthetic forecasting questions
Prediction market platforms have on the order of 100k meaningful YES/NO questions in total; and this overestimates a lot, because many of those are very correlated to each other (’Will club X win the Champions League?’). 2
This is way too little data to train on, hence the need to create synthetic data. There are two ways to do this:
Backward (from ground truth): generate questions based on reference events that happen, ask as if we were predicting the future
Forward (rejection sampling on ground truth): generate predictive questions without any reference events, discard questions that we cannot resolve in the present
Let’s first discuss the backward approach.
To create synthetic questions, you need a steady stream of “events” from reality. Scraping news sources seems like a natural way of doing this, as they are usually trustworty on factual matters.

The main advantage of the backward approach is very reliable ground truth labels (literally stated by the news article). Even GPT-4-level models could create questions about these events.
Now, an astute reader would notice: we have text of articles that serve as a ground truth reference to resolve a forecasting question. Why are we even creating forecasting questions in the first place? Why not just... train on the text of the article via next-token prediction?
To answer this, it is useful to compare this to a prototypical RL task: we are training an LLM to solve math problems using the final answer as a reward signal. Translated to this setting, I believe this is the same as asking “why RL on the final answer is better than finetuning on the final answer?” The answer is that a single forward pass is not enough. We need to train the model how to think through and produce a reasoning trace to figure out the final answer.
Of course, finetuning on existing reasoning traces is usually more efficient than RL training for the outcome. If we had reasoning traces of causal events of reality, we would not need to create synthetic data at all. The whole deal with forecasting is that we unfortunately don’t have such traces and need to train a model to figure them out.
An alternative to the above is the forward approach: just generate questions as if a person asked them in the past, and resolve them using Deep Research or similar LLM agents.
The main issue with this is that we might misresolve questions. Figuring out the state of the world in the present is not an easy task for either humans or LLMs. While questions like “What will the lowest trade of Bitcoin on 1 Jan 2026 be?” are easy to resolve, non-quantitative questions like “Military conflict between the US and Venezuela in 2026?“ are not, even when there are many LLMs available.
It is difficult a priori to know for which forecasting questions we can’t resolve, so many synthetically generated questions remain unresolved. This biases the dataset towards only containing questions that have been easy to resolve using online LLMs; this is similar to the issue in the forward pass. Even worse, the online LLM we use for resolution might misresolve the question, introducing label noise. Another, more subtle issue is that we cannot generate questions that were plausibly posed before the model training cutoff date.
For future papers, I feel more optimistic about the forward approach. Why? Because all the issues in the forward approach are “skill issues” of today’s LLMs; and future LLMs will get better at getting more precise question descriptions and resolving ambiguous questions correctly. On the other hand, the backward approach is kind of limited in scope by taking only trustworthy sources reporting on world events as ground truth; and it’s very hard to not induce logical leakage this way.
Here is a free research idea: retroactive post-mortem analysis of where the forecast went wrong (or, in case it was correct, whether it got lucky) can help with credit assignment. This might not be compute-efficient for RL in general compared to just training on more data; but in forecasting we are uniquely data-limited compared to other domains.
Those readers who have scraped certain platforms for questions will know that multiple-choice questions can get modeled as multiple YES/NO questions behind the scenes. For comparison, the original 14B Qwen-R1 model used in the Outcome-based RL paper was distilled from DeepSeek R1 on 800k math problems.
This article comes at the perfect time! Realy insightful, thank you. RL's potential is truly immense.